728x90
반응형
SMALL
📃 논문 https://arxiv.org/pdf/1505.04597.pdf
Semantic Segmantation 이란?
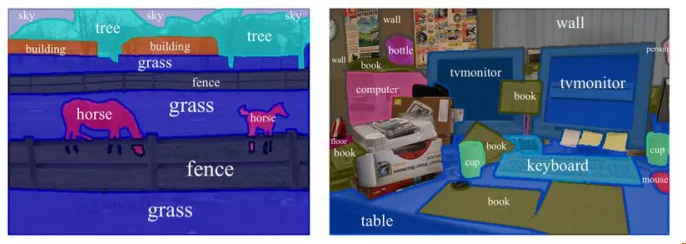
- 모든 픽셀을 해당하는 (미리 지정된 개수의) class로 분류하는 것
- dense prediction 이라고도 불림
Preview
- biomedical image processing을 위해 localization 정보를 얻기 위해 sliding-window 방법을 사용
- sliding-window의 2가지 단점을 보완
- 네트워크가 각 패치에 대해 개별적으로 실행되어야 하고 패치가 겹쳐 중복성이 많기 때문에 상당히 느림
- localization과 context사이에는 trade-off가 있는데, 이는 큰 사이즈의 patches는 많은 max-pooling을 해야해서 localization의 정확도가 떨어질 수 있고, 반면 작은 사이즈의 patches는 협소한 context만을 볼 수 있음
Main Ideas
1. U-Net Architecture

- 가운데를 기준으로 activation map 크기가 줄어드는 왼쪽 부분인 Contracting path와activation map의 크기가 증가하는 오른쪽 부분인 Expansive path로 나뉨
- 해당 구조는 Fully Convolution + Deconvolution 구조의 조합
- Contracting Path
- 전형적인 Convolution network
- 두번의 3X3 convolution을 반복 수행하며 (unpadded convolution를 사용)
- ReLU를 사용
- 2X2 max pooling 과 stride 2를 사용
- downsampling시에는 2배의 feture channel을 사용
- Expansive path
- 2X2 convolution (up-convolution)을 사용
- feature channel은 반으로 줄여 사용합
- Contracting Path에서 Max-Pooling 되기 전의 feature map을 Crop 하여 Up-Convolution 할 때 concatenation
- 두번의 3X3 convolution 반복
- ReLU를 사용
- 마지막 Final Layer에서는 1X1 convolution을 사용하여 2개의 클래스로 분류
- U-Net은 총 23개의 convolution layer가 사용
2. Overlap-tile
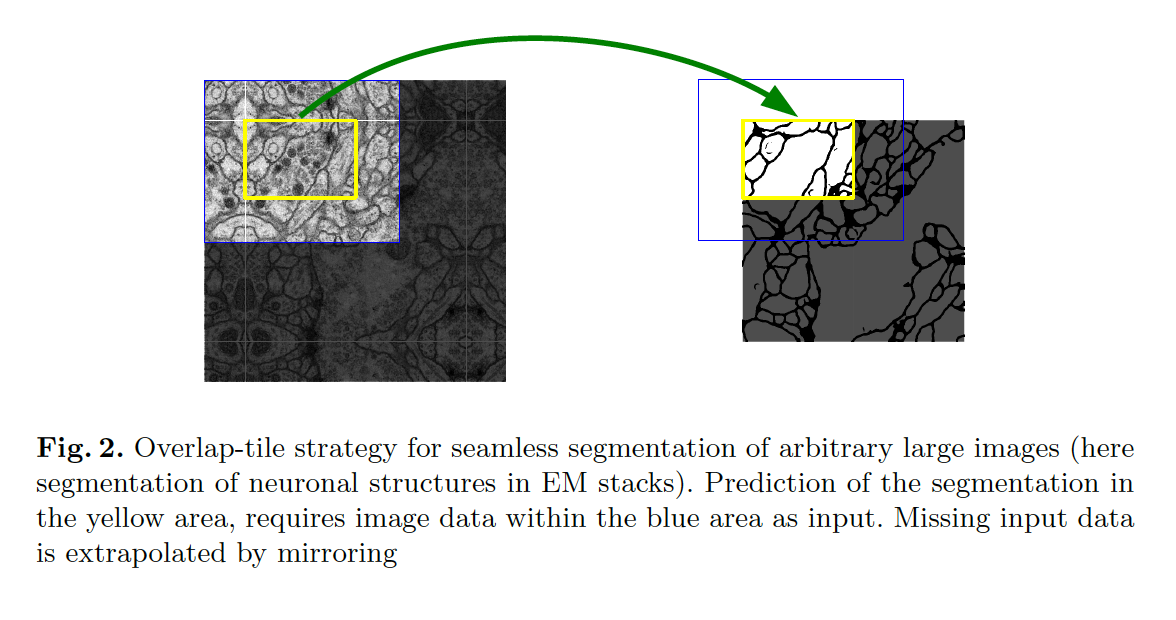
- U-Net에서 다루는 전자 현미경 데이터의 특성상 이미지 사이즈의 크기가 상당히 크기 때문에 Patch 단위로 잘라서 Input 으로 넣음
- 이때 Fig.2에서 보는 것과 같이 Border 부분에 정보가 없는 빈 부분을 0으로 채우거나, 주변의 값들로 채우거나 이런 방법이 아닌 Mirroring 방법으로 pixel의 값을 채워주는 방법을 사용
- 노랑색 영역이 실제 세그멘테이션 될 영역이고, 파랑색 부분이 Patch
- 거울처럼 반사되어 border부분이 채워짐

3. Data Augmentation

- Sementic segmentation은 pixel 별로 class labeling 해주어야 해서 학습 데이터가 적은 편
- 논문에서 언급한 data augmentation 방식은 총 4가지
- Shift
- Rotation
- Gray value
- Elastic Deformation
- Pixel이 랜덤하게 다른 방향으로 뒤틀리도록 변형하는 방식
- 이러한 기법들을 활용하여 데이터를 증가
Training UNet
Optimizer Stochastic Gradient Descent(SGD)
Momentum: 0.99
Deep learning framework : Caffe
Batch: A Single Image
Loss function

- Cross Entropy 와 Final feature map에서의 pixel-wise-max를 결합하여 계산함
- pixel-wise-max
- pixel position x에서 feature channel k에 대한 activation 확률값
- 모든 클래스에 대하여 soft-max를 거침
- pixel-wise-max
- 각 픽셀의 정답 라벨에 대한 activation이 작게 되면 큰 패널티를 부여
- 각 정답 segmentation의 weight map은 특정 class에만 편재되어있는 pixel의 frequency를 보정하고, 작은 구분 경계들을 학습하기 위해 사전계산 됨.
Conclusion
- Bio-medical에서 우수한 성능 달성
- Elastic deformation을 통한 data augmentation으로 annotation image가 거의 필요하지 않음
- NVidia Titan GPU(6GB) 환경에서 6시간의 합리적인 학습 시간
- Caffe 기반의 학습된 네트워크 제공

728x90
반응형
LIST
'AI Paper Review' 카테고리의 다른 글
| [논문 리뷰] Computer Vision - DETR (0) | 2023.09.10 |
|---|---|
| [논문 리뷰] Computer Vision - Retina(Focal Loss for Dense Object Detection) (0) | 2023.09.09 |
| [논문 리뷰] Computer Vision - Mask R-CNN (0) | 2023.09.08 |
| [논문 리뷰] Computer Vision - YOLO(You Only Look Once:Unified, Real-Time Object Detection) (0) | 2023.09.07 |
| [논문 리뷰] Computer Vision - Faster R-CNN (0) | 2023.09.06 |



