📃 논문 https://arxiv.org/pdf/2005.12872.pdf
- DETR(DEtection TRansformer)
- DETR은 Transformer 구조를 활용하여, end-to-end로 object detection을 수행하면서도 높은 성능을 보임
- 현재 많은 SOTA 모델들이 DETR을 기반으로 발전함
기존의 Object Detecor vs DETR
- 본 논문에서 object detection은 Set 타입의 bounding box와 category로 예측하는 task라고 정의

기존의 Object Detector

- pre-defined anchor를 사용
- 이미지 내 고정된 지점마다 다양한 scale, aspect ratio를 가진 anchor를 생성
- 이후 anchor를 기반으로 생성한 예측 bounding box와 ground truth를 matching
- Matching 시, ground truth와의 IoU 값이 특정 threshold 이상일 경우 positive sample으로, 이하일 경우 negative sample로 간주하며, positive sample에 대해서만 bounding box regression을 수행
- Threshold를 기준으로 독립적으로 prediction을 수행하기 때문에 하나의 ground truth에 다수의 bounding box가 matching됨 → 예측한 bounding box와 ground truth의 관계가 many-to-one
- 하나의 ground truth를 예측하는 다수의 bounding box가 존재하기 때문에, 이러한 near-duplicate한 예측(중복), 불필요한 예측을 제거하기 위해 NMS(Non Maximum Suppression)과 같은 후처리 과정이 반드시 필요
DETR

- DETR은 여러 크기의 직접 정의한 hand-crafted anchor를 사용하지 않음
- 하나의 ground truth에 오직 하나의 예측된 bounding box만 matching(one-to-one)
- 불필요한 bounding box가 없음(후처리 과정이 필요하지 않음)
Contribution
- object detection을 direct set prediction으로 정의하여, transformer와 bipartite matching loss를 사용한 DETR
- DETR은 COCO datasets에 대하여 Faster R-CNN과 비슷한 성능
- self-attention을 통한 global information(전역 정보)를 활용함으로써 크기가 큰 객체를 Faster R-CNN보다 훨씬 잘 포착
- self-attention: 입력 시퀀스의 각 위치에서 다른 위치와의 관계를 계산하는 메커니즘으로 각 입력 토큰은 다른 토큰과의 관련성을 가중치로 나타내는 벡터를 생성함.
- 이로써 모델이 문맥을 고려하면서 입력 시퀀스를 처리할 수 있음
Preliminaries
- 본 논문을 이해하기 위해 필요한 사전지식
Hungarian algorithm
- loss를 최소화할 수 있는 matching을 찾기 위해 가능한 모든 조합 경우의 수를 고려하는 brute force 방법을 사용하면 지나치게 많은 시간이 걸림 → Hungarian algorithm을 사용
- 두 집합 사이의 일대일 대응 시 가장 비용이 적게 드는 bipartite matching(이분 매칭)을 찾는 알고리즘
- 가장 적은 cost가 드는 matching에 대한 순열조합을 찾는 것
✅ 예시

- loss를 최소화할 수 있는 matching을 찾기 위해 가능한 모든 조합 경우의 수를 고려하는 brute force 방법을 사용하면 지나치게 많은 시간이 걸림 → Hungarian algorithm을 사용
- 두 집합 사이의 일대일 대응 시 가장 비용이 적게 드는 bipartite matching(이분 매칭)을 찾는 알고리즘
- 가장 적은 cost가 드는 matching에 대한 순열조합을 찾는 것

- permutation을 [3, 4, 1, 5, 2]인 경우, cost가 12로 상대적으로 매우 낮으며 가장 바람직하게 matching
💡 Hungarian algorithm은 cost에 대한 행렬을 입력 받아,matching cost가 최소인 permutation을 출력하는 algorithm
Bounding Box Loss
- DETR은 어떠한 initial guess(anchor)가 없이 bounding box를 예측하기 때문에 예측하는 값의 범주가 상대적으로 큼
- 따라서 절대적인 거리를 측정하는 l1 loss만을 사용할 경우, 상대적인 error는 비슷하지만 크기가 큰 box와 작은 box에 대하여 서로 다른 범위의 loss를 가짐(큰 box는 큰 loss를, 작은 box는 작은 loss를)
- 본 논문에서는 l1 loss와 generalized IoU(GIoU) loss를 함께 사용

※ Generalized IoU(GIoU) loss

- 두 box 사이의 IoU(Intersection over Union) 값을 활용한 loss
- scale-invarinat 하다는 특징
Transformer for NLP task vs DETR Transformer

- DETR은 효과적인 matching을 위해 encoder-decoder 구조의 Transformer를 사용
- Transformer의 self-attention은 모든 입력 sequence의 token 사이의 상호작용(pairwise interaction)을 모델링하기 때문에 set prediction에 적합
- DETR에서 사용하는 Transformer와 NLP task에서 사용하는 Transformer는 입출력 측면에서 다섯 가지 차이점
- DETR는 encoder에서 이미지 feature map을 입력 받는 반면, Transformer는 문장에 대한 embedding을 입력받음
- DETR은 x, y axis가 있는 2D 크기의 feature map을 입력 받기 때문에 기존의 positional encoding을 2D 차원으로 일반화시켜 spatial position encoding
- Transformer는 decoder에 target embedding을 입력하는 반면, DETR은 object queries(길이가 N인 학습 가능한 embedding)를 입력
- Transformer는 decoder에서 첫 번째 attention 연산 시 masked multi-head attention을 수행하는 반면, DETR은 multi-head self-attention을 수행
- DETR은 입력된 이미지에 동시에 모든 객체의 위치를 예측하기 때문에 별도의 masking 과정을 필요x
- Transformer는 Decoder 이후 하나의 head를 가지는 반면, DETR는 두 개의 head를 가짐(bounding box & class probability)
Method
- object detection 시 direct set prediction을 위해 두 가지 요소가 필수적
1. Set prediction loss
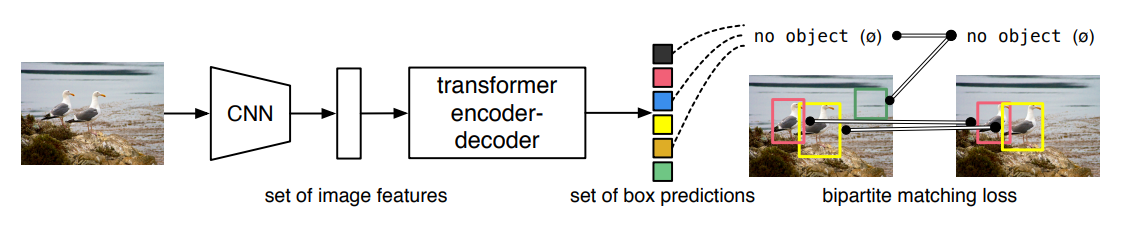
- 고정된 크기의 N개의 prediction만을 수행함으로써, 수많은 anchor를 생성하는 과정을 우회함(N은 일반적으로 이미지 내 존재하는 객체의 수보다 훨씬 더 큰 수로 지정)
- DETR을 통해 예측하는 객체의 수는 최대 N개임
- 이미지 내 객체의 수가 3개이면, y(N)에서 97개는 ∅로 pad 됨
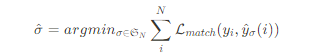
- 두 개의 set에 대하여 bipartite matching을 수행하기 위해, 아래의 cost를 minimize할 수 있는 N의 permutation을 탐색
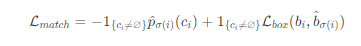
- matching cost는 class prediction과 predicted bounding box와 ground truth box 사이의 similarity(유사도)를 모두 고려
2. Architecture
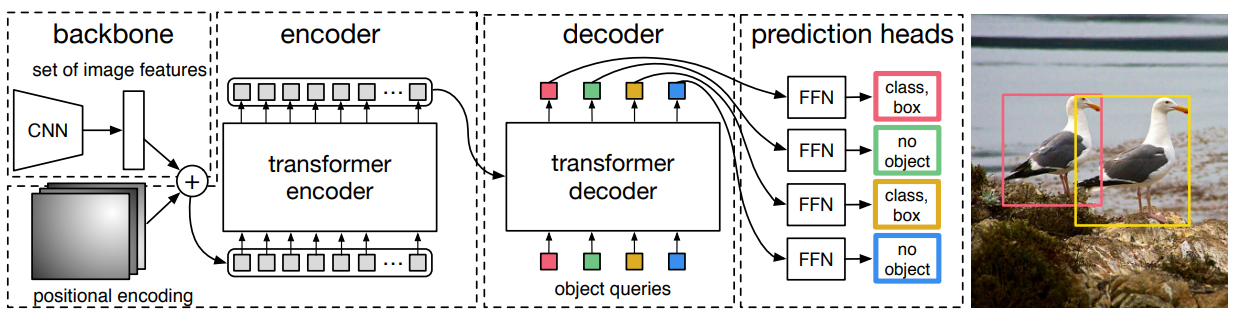
1) CNN backbone
- 입력 이미지를 CNN backbone network에 입력하여 feature map을 생성
2) Transformer encoder와 decoder
- Transformer encoder
- 1x1 convolution 연산을 적용
- 각 encoder layer는 multi-head self-atttention module과 feed forward network(FFN)으로 구성
- encoder layer 입력 전에 입력 embedding에 positional encoding을 더해줌
- Transformer decoder
- DETR의 decoder는 N개의 object에 대한 정보를 한번에 출력
- permutation-invariant하기 때문에 입력으로 받는 embedding으로 object queries라고 불리는 learnt positional encoding을 사용
- encoder와 유사하게 object query를 각 attention layer의 입력에 더해줌
- embedding은 self-attention과 encoder-decoder attention을 통해 이미지 내 전체 context에 대한 정보를 사용
- 객체 사이의 pair-wise relation을 포착하여 객체간의 전역적(global)인 정보를 모델링하는 것이 가능
3) FFN(Feed Forward Network)s
- Decoder에서 출력한 output embedding을 3개의 linear layer와 ReLU activation function으로 구성된 FFN에 입력하여 최종 예측을 수행
- FFN은 이미지에 대한 class label과 bounding box에 좌표(normalized center coordinate, width, height)를 예측
- 예측하는 class label 중 ∅은 객체가 포착되지 않은 경우로, "background" class를 의미
4) Auxiliary decoding losses
- 학습 시, 각 decoder layer마다 FFN을 추가하여 auxiliary loss를 구함
- 이러한 보조적인 loss를 사용할 경우 모델이 각 class별로 올바른 수의 객체를 예측하도록 학습시키는데 도움을 줌
- 추가한 FFN은 서로 파라미터를 공유하며, FFN 입력 전에 사용하는 layer normalization layer도 공유
Training Procedure
1) Extract feature map by CNN backbone
- CNN backbone인 ResNet에 입력하여 feature map f∈RC×h×w추출
💡 Input : image ximg∈R^(3×H×W)
Output : feature map f∈R^(C×h×w)
2) Add Positional Encoding
- feature map f을 1x1 convolution layer에 입력한 후 spatial dimension을 collapse
- flatten된 feature map에 대한 spatial positional encoding을 구함
- spatial positional encoding은 Encoder의 모든 multi-head self-attention layer에서 query와 key에 더해짐
💡 Input : feature map f∈R^(C×h×w)’
Output : feature map z0∈R^(d×hw), positional encoding P∈R^(d×hw)
3) Generate Object queries
- query feature 와 query positional embedding 를 생성
💡 Input : query feature qf∈R^(N×d), query positional embedding qp∈R^(N×d)
Output : object query q∈R^(N×d)
4) Output encoder memory by Transformer encoder
- Encoder는 feature map을 입력받아 multi-head self-attention, feed forward network를 거쳐 feature map에 대한 representation을 학습한 encoder memory를 출력
- encoder memory는 모든 decoder의 multi-head attention layer에 전달
💡 Input : feature map z0∈R^(d×hw), positional encoding P∈R^(d×hw)]
Output : encoder memory oe∈R^(hw×d)
5) Output output embedding by Transformer decoder
- Decoder는 object queries를 입력받아 multi-head self attention layer를 거친 후, encoder memory 와 multi-head attention을 수행
- 이후 feed forward network를 거쳐 output embedding을 출력
💡 Input : object queries q∈R^(N×d), encoder output embedding oe∈R^(hw×d)
Output : output embedding od∈R^(hw×d)/
6) Class prediction by Class head
- Class prediction head는 Decoder의 output embedding를 입력받아, fully connected layer를 통해 N개의 prediction에 대한 class prob을 출력
- Class의 수가 c라고 할 때 배경까지 고려하여 c+1개의 class를 예측
💡 Input : output embedding od∈R^(hw×d)
Output : class prob p(ci)∈R^(N×(c+1))
7) Bounding box prediction by Bounding box head
- Bounding box head는 Decoder의 output embedding를 입력받아 fully connected layer를 통해 N개의 prediction에 대한 bounding box coordinate를 출력
💡 Input : output embedding od∈R^(hw×d)
Output : bounding box coordinates b∈R^(N×4)
8) Match prediction with ground truth by Hungarian Matcher
- class head와 bounding box head를 통해 N개의 class prob와 bounding box를 예측한 것을 기반으로 matching cost matrix를 활용하여 Hungarian matcher를 통해 prediction과 ground truth 사이의 matching cost를 최소화할 수 있는 최적의 permutation 을 탐색
💡 Input : class prob p(ci)∈RN×(c+1), bounding box coordinates b∈R^(N×4)
Output : permutation σ(i)
9) Compute losses
- Hungarian matcher를 통해 구한 permutation σ(i)으로 matching된 prediction과 ground truth 사이의 loss를 구함
💡 Input : class prob p(ci)∈R^(N×(c+1)), bounding box coordinates b∈R^(N×4), permutation σ(i)
Output : total loss LHungarian(y,^y)
Experiments
- Comparison with Faster R-CNN
- COCO dataset에 대한 실험 결과, DETR은 같은 수의 파라미터로 Faster R-CNN과 비슷한 수준의 성능
- DETR for panoptic segmentation
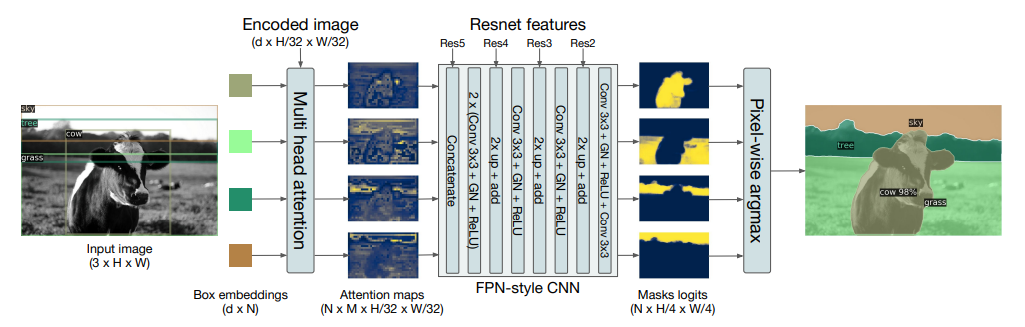
- DETR은 panoptic segmentation task에도 확장 가능함을 보임
- panoptic segmentation은 semantic- instance segmentation을 결합한 task
- Decoder output에 mask를 예측하는 head를 추가함으로써 segmentation을 수행할 수 있음
- 여러 크기의 anchor를 사용하지 않기 때문에 다양한 크기, 형태의 객체를 포착하지 못함
- 하나의 예측 bounding box를 ground truth에 matching하기 때문에 converge하는데 훨씬 긴 학습시간을 필요
- 본 논문에서 제안한 DETR은 Faster R-CNN과 비슷한 성능을 보이면서도 heuristic한 과정이나 post-processing을 필요하지 않다는 점에서 큰 의의를 가짐

'AI Paper Review' 카테고리의 다른 글
| [논문 리뷰] Computer Vision - YOLOv9: 물체 감지 기술의 도약 (0) | 2024.03.06 |
|---|---|
| [논문 리뷰] Computer Vision - SOLO(Semgmentation Objects by LOcation) (0) | 2023.10.04 |
| [논문 리뷰] Computer Vision - Retina(Focal Loss for Dense Object Detection) (0) | 2023.09.09 |
| [논문 리뷰] Computer Vision - UNet (0) | 2023.09.08 |
| [논문 리뷰] Computer Vision - Mask R-CNN (0) | 2023.09.08 |



