728x90
반응형
SMALL
📃 논문 https://arxiv.org/pdf/1703.06870.pdf
Instance Segmentation?

- 이미지 내에 존재하는 모든 객체를 탐지하는 동시에 각각의 경우(instance)를 정확하게 픽셀 단위로 분류하는 task
- 객체를 탐지하는 object detection task와 각각의 픽셀의 카테고리를 분류하는 semantic segmentation task가 결합
Preview
- Faster R-CNN의 RPN에서 얻은 RoI(Region of Interest)에 대하여 객체의 class를 예측하는 classification branch + bbox regression을 수행하는 bbox regression branch와 평행으로 segmentation mask를 예측하는 mask branch
- mask branch는 각각의 RoI에 작은 크기의 FCN(Fully Convolutional Network)가 추가된 형태
Main Ideas
1. Mask branch
- backbone network를 통해 얻은 feature map을 RPN(Region Proposal Network)에 입력하여 RoIs(Region of Interests)를 얻음.
- RoI pooling을 통해 고정된 크기의 feature map을 얻고 이를 fc layer에 입력한 후 classification branch와 bbox regression branch에 입력하여 class label과 bbox offset이라는 두 가지 결과를 예측
- 두 branch와 평행(pararell)으로 segmentation mask를 예측하는 mask branch가 추가된 구조
- RoI pooling을 통해 얻은 고정된 크기의 feature map을 mask branch에 입력하여 segmentation mask를 얻음.
- segmentation mask: class에 따라 분할된 이미지 조각(segment)
- mask branch는 여러 개의 conv layer로 구성된 작은 FCN의 구조
- mask branch는 각각의 RoI에 대하여 class별로 binary mask를 출력
- Mask R-CNN은 class별로 mask를 생성한 후 픽셀이 해당 class에 해당하는지 여부를 표시
- mask branch는 최종적으로 K²m 크기의 feature map을 출력
- m은 feature map의 크기, K는 class의 수
2. RoI Align
- misalignment의 문제점

- RoI pooling으로 인해 얻은 feature와 RoI 사이가 어긋나는 문제가 발생
- 이런 어긋남은 pixel mask를 예측하는데 매우 안 좋은 영향을 끼침
- 논문에서는 RoI pooling 방식이 quantization 과정을 수반하여 misalignment를 유도한다고 봄
- quantization: 실수(floating) 입력값을 정수와 같은 이산 수치(discrete value)으로 제한하는 방법
[RoI Align 과정]
- RoI projection을 통해 얻은 feature map을 quantization 과정 없이 그대로 사용
- 출력하고자 하는 feature map의 크기에 맞게 projection된 feature map을 분할
- 분할된 하나의 cell에서 4개의 sampling point를 찾음
- **Bilinear interpolation(선형 보간법)**을 적용
- 모든 cell에 대하여 반복

- 하나의 cell에 있는 4개의 sampling point에 대하여 max pooling을 수행
💡 RoI의 정확한 spatial location을 보존하는 것이 가능해짐! →mask accuracy가 크게 향상
3. Loss Function
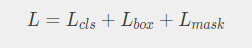
- Mask R-CNN은 위와 같이 구성된 multi-task loss function을 통해 네트워크를 학습
- class branch와 mask branch를 분리하여 class별로 mask를 생성한 후 binary loss를 구함
4. Backbone Network
- Mask R-CNN은 backbone network로 ResNet-FPN을 사용
Training Mask R-CNN
- 이미지 및 feature map에 대한 전처리, 후처리 필요
1) Input image Pre-processing
- 원본 이미지의 width, height 중 더 짧은 쪽(shorter edge)이 target size로 resize
- 더 긴 쪽(longer edge)은 가로세로비율을 보존하는 방향으로 resize
- 만약 더 긴 쪽이 maximum size를 초과하면 maximum size로 resize되고 더 짧은 쪽이 가로세로비율을 보존하는 방향을 resize
- target size, maximum size의 디폴트값은 각각 800, 1333
💡 Input : image
Process : image pre-processing
Output : resized image
2) Feature pyramid by backbone network
- 전처리된 이미지를 ResNet-FPN backbone network에 입력하여 feature pyramid {P2, P3, P4, P5, P6}를 얻음
💡 Input : resized image
Process : constructing feature pyramid
Output : feature pyramid {P2, P3, P4, P5, P6}
3) Region proposal by RPN
- feature pyramid별로 **RPN(Region Proposal Network)**에 입력하여 objectness score과 bbox regressor를 가진 Region proposal을 출력
💡 Input : feature pyramid {P2, P3, P4, P5, P6}
Process : Region proposal
Output : Region proposals with objectness score and bbox regressor per feature pyramid {P2, P3, P4, P5, P6}
4) Select best RoI by Proposal layer
- RPN을 통해 얻은 Region proposal 중 최적의 RoI를 선정
- 1) objectness score가 높은 top-k개의 anchor를 선정(학습 시 k=12000로 설정)
- 2) bbox regressor에 따라 anchor box의 크기를 조정
- 3) 이미지의 경계를 벗어나는 anchor box를 제거
- 4) threshold=0.7로 지정하여 Non maximum suppression을 수행
- 5) 지금까지의 과정은 각각의 feature pyramid level별({P2, P3, P4, P5, P6})로 수행됨. 이전 과정까지 얻은 모든 feature pyramid level의 anchor box에 대한 정보를 결합
- 6) 마지막으로 결합된 모든 anchor box에 대하여 objectness score에 따라 top-N개의 anchor box를 선정(학습 시 N=2000로 설정)
- 최종적으로 수많은 anchor box 중 최적의 N개의 box만이 학습에 사용
💡 Input : Region proposals
Process : selecting top-N RoIs
Output : top-N RoIs
5) feature map by RoI Align layer
- feature pyramid는 multi-scale feature map이기 때문에 RoI를 어떤 scale의 feature map과 매칭시킬지를 결정하는 과정이 필요
- RoI와 feature map을 사용하여 RoIAlign 과정을 통해 7x7 크기의 feature map을 출력
💡 Input : feature pyramid and RoIs
Process : RoIAlign
Output : 7x7 sized feature map
6. Classification and Bounding box regression by Fast R-CNN

- RoIAlign 과정을 통해 얻은 7x7 크기의 feature map을 fc layer를 거쳐 classfication branch, bbox regression branch에 전달 → 최종적으로 class score과 bbox regressor을 도출
💡 Input : 7x7 sized feature map
Process : classification by classification branch, bbox regressor by bbox regression branch
Output : class scores and bbox regressors
7) Mask segment by Mask branch
- RoIAlign 과정을 통해 얻은 7x7 크기의 feature map을 mask branch에 전달(feature map은 class별로 생성된 binary mask)
- 14x14(xK) 크기의 feature map 중 앞서 classification branch에서 얻은 가장 높은 score의 class에 해당하는 feature map을 선정하여 최종 prediction에 사용
💡 Input : 7x7 sized feature map
Process : mask segment by mask branch
Output : 14x14 sized feature map
8) Post-processing of masks
- 최종적으로 선정된 14x14 크기의 featue map을 원본 이미지의 mask와 비교하기 위해 rescale해주는 과정을 수행
- mask threshold(=0.5)에 따라 mask segment의 각 픽셀값이 0.5 이상인 경우 class에 해당하는 객체가 있어 1을 할당하고, threshold 미만의 경우 0을 할당
💡 Input : 14x14 sized feature map
Process : rescale and apply mask threshold
Output : mask segment
9) Train Mask R-CNN by multi-task loss
- Mask R-CNN 네트워크를 위에서 언급한 multi-task loss function을 사용하여 학습
Inference

- COCO 데이터셋을 학습에 사용한 결과, AP값이 37.1%
- instance segmentation task에서 가장 좋은 성능을 보인 FCIS+++와 OHEM을 결합한 모델보다 AP값이 2.5% 더 높게 나옴

728x90
반응형
LIST
'AI Paper Review' 카테고리의 다른 글
| [논문 리뷰] Computer Vision - Retina(Focal Loss for Dense Object Detection) (0) | 2023.09.09 |
|---|---|
| [논문 리뷰] Computer Vision - UNet (0) | 2023.09.08 |
| [논문 리뷰] Computer Vision - YOLO(You Only Look Once:Unified, Real-Time Object Detection) (0) | 2023.09.07 |
| [논문 리뷰] Computer Vision - Faster R-CNN (0) | 2023.09.06 |
| [논문 리뷰] Computer Vision - Fast R-CNN (0) | 2023.09.06 |



