728x90
반응형
SMALL
📄 사용 데이터셋 - 코로나 흉부 X-ray데이터
Covid19-dataset.zip
drive.google.com
- Covid19-dataset.zip
- VGG19(Classification) 모델
- Dataset, Dataloader, Train/Val 클래스화
- Test 셋에 대한 예측 및 결과를 시각화
1. 가상환경 만들기
- 가상환경 설치
pip install pipenv- 가상환경에서 사용할 파이썬 버전 지정
pipenv --python 3.8- 가상환경 실행
pipenv shell- 가상환경을 관리하는 ipykernel 패키지 설치
pipenv install ipykernel- 주피터노트북에서 사용할 가상환경 이름 설정
python -m ipykernel install --user --display-name (주피터노트북에 표기할 커널이름) --name (가상환경 이름)
python -m ipykernel install --user --display-name yesung2 --name yesung2
2. 필요한 모듈 설치 및 불러오기
!pip install opencv-python
!pip install matplotlib
!pip install torch
!pip install torchvision
!pip install interact※ 주피터노트북에서 !pip로 설치가 안될경우 cmd에서 pipenv 패키지명
import os
import cv2
import matplotlib.pyplot as plt
import torch
import copy
import warnings
warnings.filterwarnings('ignore') # WARNING 뜨는거 안보이게
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
import torch.nn as nn
from ipywidgets import interact
3. 이미지 파일을 모두 불러오기
image_files = []
# data_dir: Covid19-dataset/train
# sub_dir: Normal(클래스명)
# 이미지의 경로들을 리스트로 만드는 함수
def list_image_file(data_dir, sub_dir):
image_format = ['jpeg', 'jpg', 'png']
image_files = []
image_dir = os.path.join(data_dir, sub_dir) #Covid19-dataset/train/Normal
# print(image_dir)
for file_path in os.listdir(image_dir): # ./Covid19-dataset/train/Normal 안에 있는 이미지 데이터들을 list로 불러옴
# print(file_path)
if file_path.split('.')[-1] in image_format: # 파일리스트의 형식이 이미지의 형식리스트 안에 있는 데이터라면
image_files.append(os.path.join(sub_dir, file_path))
return image_files
data_dir = './Covid19-dataset/train/' # train 데이터셋이 있는 경로
normals_list = list_image_file(data_dir, 'Normal')
covids_list = list_image_file(data_dir, 'Covid')
pneumonias_list = list_image_file(data_dir, 'Viral Pneumonia')
covids_list
# 각 경로별 데이터 리스트의 개수
print(len(normals_list))
print(len(covids_list))
print(len(pneumonias_list))
>>> 70
111
70# 파일 경로를 불러들여 RGB 데이터로 변환하여 읽어오는 함수
def get_RGB_image(data_dir, file_name):
image_file = os.path.join(data_dir, file_name)
image= cv2.imread(image_file)
image= cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return image# interact 모듈을 사용하여 여러개의 이미지를 3개씩 출력해보자
min_num_files = min(len(normals_list), len(covids_list), len(pneumonias_list))
# 인덱스 범위를 줌(70개), 조절바를 움직일때마다 아래 함수를 실행시킴
@interact(index=(0, min_num_files-1))
def show_samples(index=0):
normal_image = get_RGB_image(data_dir, normals_list[index]) # 인덱스에 해당하는 파일들을 RGB 형태로 변환
covid_image = get_RGB_image(data_dir, covids_list[index])
pneumonia_image = get_RGB_image(data_dir, pneumonias_list[index])
plt.figure(figsize=(12,8))
plt.subplot(131)
plt.title('Normal')
plt.imshow(normal_image)
plt.subplot(132)
plt.title('Covid')
plt.imshow(covid_image)
plt.subplot(133)
plt.title('Pneumonia')
plt.imshow(pneumonia_image)
plt.tight_layout()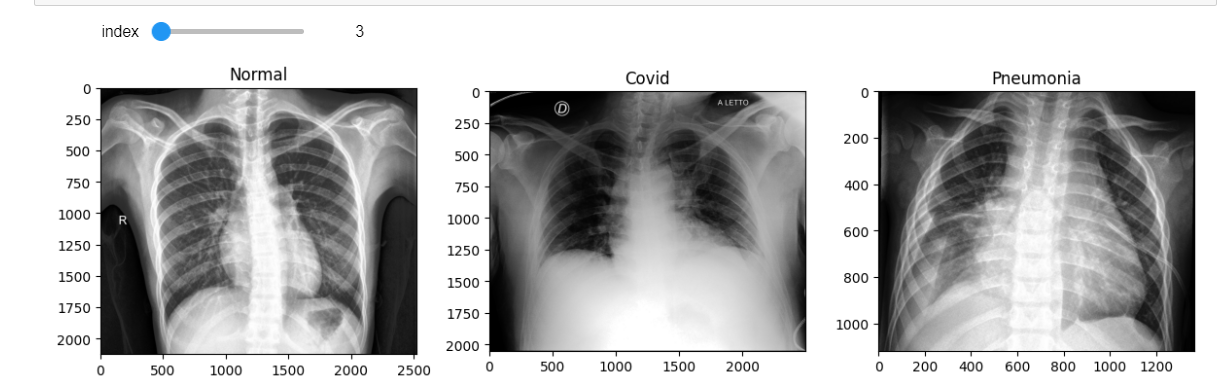
4. 데이터셋 설정
train_data_dir = './Covid19-dataset/train/'
class_list = ['Normal', 'Covid', 'Viral Pneumonia']
class Chest_dataset(Dataset): # torch에서 제공하는 Dataset 클래스를 상속받음
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir
normals = list_image_file(data_dir, 'Normal')
covids = list_image_file(data_dir, 'Covid')
pneumonias = list_image_file(data_dir, 'Viral Pneumonia')
self.files_path = normals + covids + pneumonias # 모든 데이터들을 합침
self.transform = transform
def __len__(self):
return len(self.files_path)
def __getitem__(self, index):
image_file = os.path.join(self.data_dir, self.files_path[index])
image = cv2.imread(image_file)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 라벨을 같이 뽑아주기 위해 - 라벨은 폴더명임!
# index: 0, 1, 2 형태로 나옴
# os.sep(\\)를 기준으로 split한 다음에 -2는 폴더명
target = class_list.index(self.files_path[index].split(os.sep)[-2])
if self.transform: # 넘어온 transform이 있다면
image = self.transform(image)
target = torch.Tensor([target]).long() # 텐서로 감싼 다음 정수로 변환
return {'image': image, 'target':target}4-1. transfomer 생성
# transform 만들기
transformer = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224, 224)), # VGG 모델 input 데이터 크기 맞춤
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
✅ 학습 데이터셋
train_dset = Chest_dataset(train_data_dir, transformer)
# transform을 거쳐 변형된 이미지(텐서형, 224 * 224로 바뀌는)
index = 100
image = train_dset[index]['image']
label = train_dset[index]['target']
print(image.shape, label)
>>>
torch.Size([3, 224, 224]) tensor([1])5. 데이터로더 생성
# 데이터로더 만드는 함수
def build_dataloader(train_data_dir, val_data_dir):
dataloaders = {}
train_dset = Chest_dataset(train_data_dir, transformer)
dataloaders['train'] = DataLoader(train_dset, batch_size=4, shuffle=True, drop_last=True) # drop_last: 배치사이즈(4)만큼 했을 때 나머지들은 제거시킴
val_dset = Chest_dataset(val_data_dir, transformer)
dataloaders['val'] = DataLoader(val_dset, batch_size=1, shuffle=False, drop_last=False) # 학습 데이터가 아니기 때문에 한개씩 비교하면 됨
return dataloaders
train_data_dir = './Covid19-dataset/train/'
val_data_dir = './Covid19-dataset/test/'
dataloaders = build_dataloader(train_data_dir, val_data_dir)
# dataloaders['train']
# 배치사이즈(4)만큼 image와 target이 한바퀴만 돌려서 봄
for i, d in enumerate(dataloaders['train']):
print(i, d)
if i == 0:
break
6. VGG19모델 불러오기
- Visual Geometry Group
- 다중 레이어가 있는 표준 심층 CNN 아키텍처

# torchvision의 models를 사용
# pretrained=True: 미리 학습된 weight들을 가지고옴(전이학습)
model = models.vgg19(pretrained=True)
model
# FC 레이어부분을 수정하는 함수
def build_vgg19_based_model(device_name='cpu'):
device = torch.device(device_name)
model = models.vgg19(pretrained=True)
model.avgpool = nn.AdaptiveAvgPool2d(output_size=(1,1))
model.classifier = nn.Sequential(
nn.Flatten(), # 2차원을 1차원으로 축소
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, len(class_list)), # 클래스 개수만큼으로 output 설정
nn.Softmax(dim=1) # 각 클래스별 확률
)
return model.to(device)
model = build_vgg19_based_model(device_name='cpu')
model
✅ loss_function 정의(분류 크래스가 3개이기 때문에 CrossEntropyLoss)
loss_func = nn.CrossEntropyLoss(reduction='mean')
✅ optimizer 정의
- SGD: 배치를 랜덤하게 뽑음
- momentum: 이전 가중치를 얼마만큼 참고할것인가 (90%, SGD에서 거의 관례처럼 0.9를 씀)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)7. 모델 학습
✅ 정확도를 구하는 함수 정의
# accuracy 구하는 함수
@torch.no_grad()
def get_accuracy(image, target, model):
batch_size = image.shape[0]
prediction = model(image)
_, pred_label = torch.max(prediction, dim=1)
is_correct = (pred_label == target) # 1 또는 0으로 나옴
return is_correct.cpu().numpy().sum() / batch_size # 다 맞추면 1
✅ 학습을 위한 함수
# 학습을 위한 함수
def train_one_epoch(dataloaders, model, optimizer, loss_func, device):
losses = {}
accuracies = {}
for tv in ['train', 'val']:
running_loss = 0.0
running_correct = 0
if tv == 'train': # train모드
model.train()
else:
model.eval() # 검증 모드(가중치 업데이트안함)
for index, batch in enumerate(dataloaders[tv]):
image = batch['image'].to(device)
target = batch['target'].squeeze(dim=1).to(device)
with torch.set_grad_enabled(tv == 'train'): # gradient를 동작
prediction = model(image)
loss = loss_func(prediction, target)
if tv == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
running_correct += get_accuracy(image, target, model)
if tv == 'train':
if index % 10 == 0:
print(f"{index}/{len(dataloaders['train'])} - Running loss: {loss.item()}")
losses[tv] = running_loss / len(dataloaders[tv])
accuracies[tv] = running_correct / len(dataloaders[tv])
return losses, accuracies
✅ 학습 후 베스트 모델을 저장하는 함수
# 학습 후 베스트 모델 저장하는 함수
def save_best_model(model_state, model_name, save_dir='./trained_model'):
os.makedirs(save_dir, exist_ok=True)
torch.save(model_state, os.path.join(save_dir, model_name))
✅ 변수들을 따로 모아서 정의
device = torch.device('cpu')
train_data_dir = './Covid19-dataset/train/'
val_data_dir = './Covid19-dataset/test/'
dataloaders = build_dataloader(train_data_dir, val_data_dir)
model = build_vgg19_based_model(device_name='cpu')
loss_func = nn.CrossEntropyLoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)
✅ 모델 학습(에폭 10)
num_epochs=10
best_acc=0.0
train_loss, train_accuracy = [], []
val_loss, val_accuracy = [], []
for epoch in range(num_epochs):
losses, accuracies = train_one_epoch(dataloaders, model, optimizer, loss_func, device)
train_loss.append(losses['train'])
val_loss.append(losses['val'])
train_accuracy.append(accuracies['train'])
val_accuracy.append(accuracies['val'])
print(f"{epoch+1}/{num_epochs} - Train Loss: {losses['train']}, Val Loss: {losses['val']}")
print(f"{epoch+1}/{num_epochs} - Train Accuracy: {accuracies['train']}, Val Accuracy: {accuracies['val']}")
if (epoch > 3) and (accuracies['val'] > best_acc):
best_acc = accuracies['val']
best_model = copy.deepcopy(model.state_dict())
save_best_model(best_model, f'model_{epoch+1: 02d}.pth')
print(f'Best Accuracy: {best_acc}')
✅ 모델 학습 후 시각화
plt.figure(figsize=(6,5))
plt.subplot(211)
plt.plot(train_loss, label='train')
plt.plot(val_loss, label='val')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.grid('on')
plt.legend()
plt.subplot(212)
plt.plot(train_accuracy, label='train')
plt.plot(val_accuracy, label='val')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.grid('on')
plt.legend()
plt.tight_layout()8. 모델 테스트
✅테스트 이미지 데이터를 전처리하는 transformer
def preprocess_image(image):
transformer = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224, 224)), # VGG 모델 input 데이터 크기 맞춤
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
tensor_image = transformer(image) # 텐서이미지로 변환, C, H, W 형식
tensor_image = tensor_image.unsqueeze(0) # Batchsize, C, H, W 형식
return tensor_image
✅모델에 이미지를 넣어 예측하여 가장 높은 확률을 label로 뽑는 함수
def model_predict(image, model):
tensor_image = preprocess_image(image)
prediction = model(tensor_image)
_, pred_label = torch.max(prediction.detach(), dim=1)
print('prediction.detach(): ',prediction.detach())
print('pred_label: ',pred_label)
pred_label = pred_label.squeeze(0)
return pred_label.item()
✅ 베스트 모델 가중치 가져오기
ckpt = torch.load('./trained_model/model_09.pth')
model = build_vgg19_based_model()
model.load_state_dict(ckpt)
model.eval()
✅ 테스트 데이터로 클래스 분류 테스트
data_dir = './Covid19-dataset/test/'
test_normals_list = list_image_file(data_dir, 'Normal')
test_covids_list = list_image_file(data_dir, 'Covid')
test_pneumonias_list = list_image_file(data_dir, 'Viral Pneumonia')
class_list = ['Normal', 'Covid', 'Viral Pneumonia']
✅interact로 예측된 데이터 보기
# 인덱스 범위를 줌(70개), 조절바를 움직일때마다 아래 함수를 실행시킴
min_num_files = min(len(test_normals_list), len(test_covids_list), len(test_pneumonias_list))
@interact(index=(0, min_num_files-1))
def show_samples(index=0):
normal_image = get_RGB_image(data_dir, test_normals_list[index]) # 인덱스에 해당하는 파일들을 RGB 형태로 변환
covid_image = get_RGB_image(data_dir, test_covids_list[index])
pneumonia_image = get_RGB_image(data_dir, test_pneumonias_list[index])
prediction_1 = model_predict(normal_image, model)
prediction_2 = model_predict(covid_image, model)
prediction_3 = model_predict(pneumonia_image, model)
plt.figure(figsize=(12,8))
plt.subplot(131)
plt.title(f'Normal, Pred: {class_list[prediction_1]}')
plt.imshow(normal_image)
plt.subplot(132)
plt.title(f'Covid, Pred: {class_list[prediction_2]}')
plt.imshow(covid_image)
plt.subplot(133)
plt.title(f'Pneumonia, Pred: {class_list[prediction_3]}')
plt.imshow(pneumonia_image)
plt.tight_layout()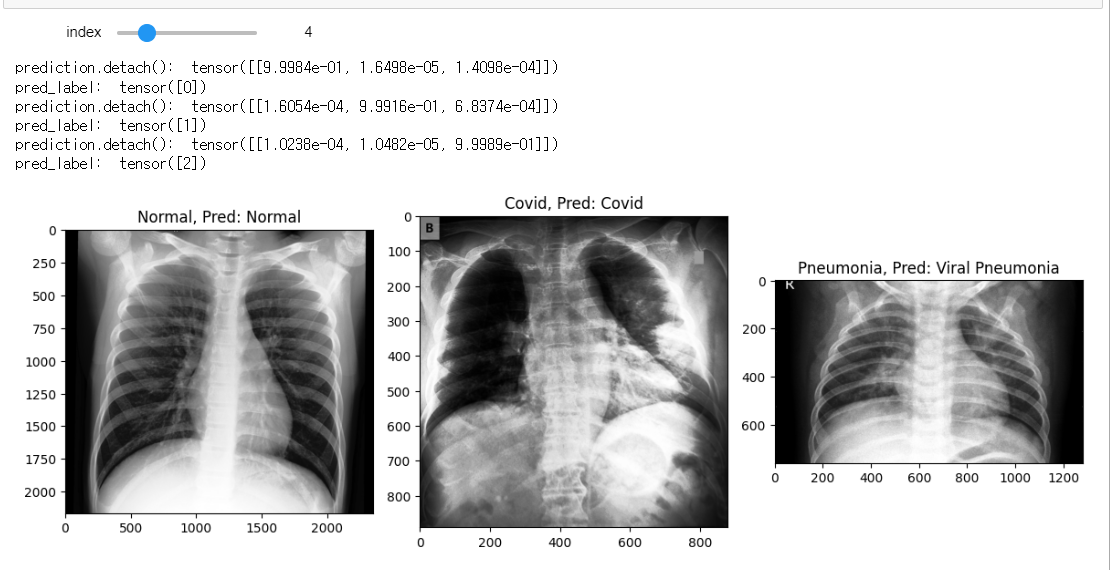
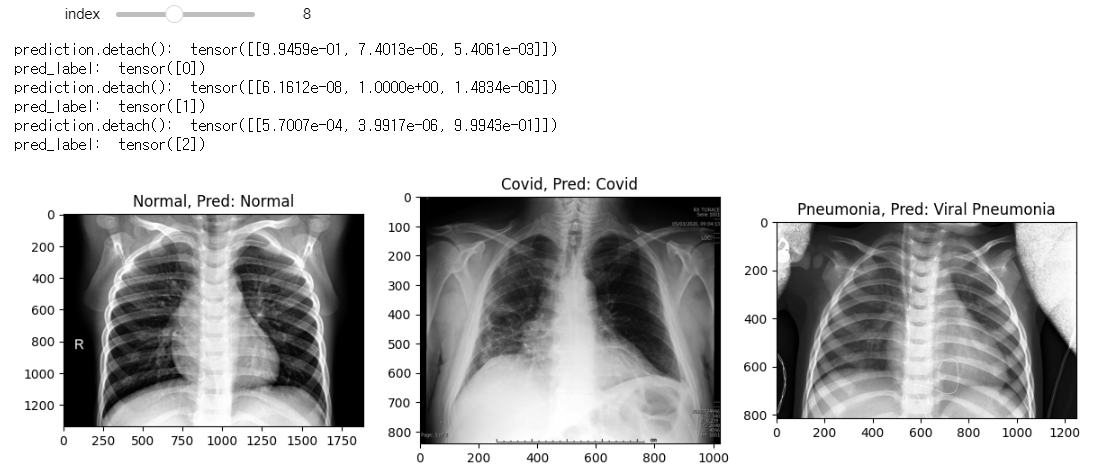
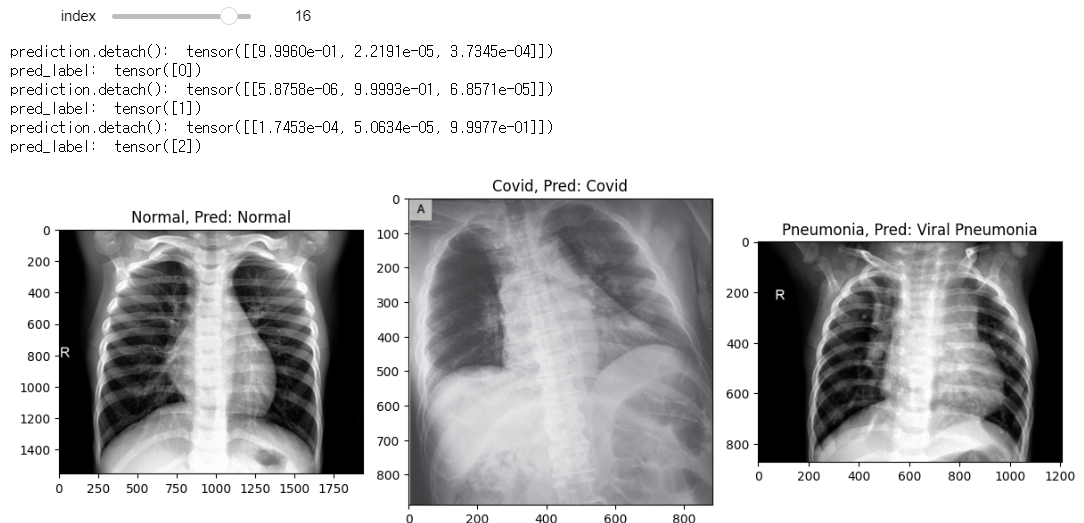
모델 학습 후 테스트 이미지로 테스트 했을 때 분류 성능이 꽤 좋은것을 확인할 수 있었다.
😎

728x90
반응형
LIST
'Python > Computer Vision' 카테고리의 다른 글
| [파이썬, Python] Computer Vision - Faster RCNN 객체 탐지 실습 (0) | 2023.09.04 |
|---|---|
| [파이썬, Python] Computer Vision - Object Detection(객체 탐지) (0) | 2023.09.04 |
| [파이썬, Python] Computer Vision - 분류(Classification), CNN과 CNN의 변천 (0) | 2023.09.04 |
| [파이썬, Python] 컴퓨터 비전(Computer Vision)의 데이터셋 (0) | 2023.09.04 |
| [파이썬, Python] OpenCV - 레이블링(labeling)과 외곽선 검출 (0) | 2023.09.02 |



