728x90
반응형
SMALL
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_20newsgroups
1. 데이터 전처리
# 영어 말뭉치 데이터셋
# remove=('header','footer','quotes')을 삭제한 데이터만 가져옴
dataset = fetch_20newsgroups(shuffle=True, random_state=10, remove=('headers','footers','quotes'))
# dataset
# dataset.data
dataset = dataset.data
dataset[0]
# 데이터셋 총 개수
len(dataset)
>>> 11314
# document 필드를 가진 데이터프레임으로 변환
news_df = pd.DataFrame({'document': dataset})
news_df
# 데이터셋에 결측값이 있는지 확인
news_df.replace('', float('NaN'),inplace=True) # 비어있는 데이터를 float형에 NaN을 변환됨
print(news_df.isna().values.any()) # 결측치가 있는지 없는지 여부를 True, False로 반환
>>> True
# 데이터셋의 결측값을 제거 후 데이터셋 총 개수
news_df = news_df.dropna().reset_index(drop=True)
print(f'결측지 제거 후 데이터셋 총 개수는 {len(news_df)}개')
>>> 결측지 제거 후 데이터셋 총 개수는 11096개
11314 - 11096 # 결측지 218개가 제거
>>> 218
news_df
# 열을 기준으로 중복된 데이터를 제거
processed_news_df = news_df.drop_duplicates(['document']).reset_index(drop=True)
processed_news_df
11096 - 10993 # 103개의 중복 데이터 제거
>>> 103
# 데이터셋에 특수 문자를 제거
processed_news_df['document'] = processed_news_df['document'].str.replace('[^a-zA-Z]', ' ')
processed_news_df
# 데이터셋에 길이가 너무 짧은 단어를 제거(단어의 길이가 2이하)
processed_news_df['document'] = processed_news_df['document'].apply(lambda x: ' '.join([token for token in x.split() if len(token) > 2]))
processed_news_df
# 전체 길이가 200 이하이거나 전체 단어 개수가 5개 이하인 데이터를 필터링
processed_news_df = processed_news_df[processed_news_df.document.apply(lambda x: len(str(x)) > 200 and len(str(x).split()) > 5)].reset_index(drop=True)
processed_news_df
# 전체 단어에 대한 소문자 변환
processed_news_df['document'] = processed_news_df['document'].apply(lambda x: x.lower())
processed_news_df
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
stop_words = stopwords.words('english')
print(len(stop_words)) # 영어로된 스톱워즈의 수
print(stop_words[:10])
# 데이터셋에 불용어를 제외하여 띄어쓰기 단위로 문장을 분리
tokenized_doc = processed_news_df['document'].apply(lambda x: x.split())
tokenized_doc = tokenized_doc.apply(lambda x: [s_word for s_word in x if s_word not in stop_words])
tokenized_doc
tokenized_doc = tokenized_doc.to_list()
print(len(tokenized_doc))
>>> 81992. 토큰화
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(tokenized_doc) # 토큰화
word2idx = tokenizer.word_index
# word2idx
idx2word = {value:key for key, value in word2idx.items()} # 인덱스와 values값 순서 변경하고 딕셔너리
encoded = tokenizer.texts_to_sequences(tokenized_doc)
idx2word
encoded # 인덱스 번호

vocab_size = len(word2idx) + 1
print(f'단어 사전의 크기: {vocab_size}')
>>> 단어 사전의 크기: 70992
print(encoded[0])
# Negative Sampling을 위해 keras에서 제공하는 전처리 도구 skipgrams를 사용
from tensorflow.keras.preprocessing.sequence import skipgrams
# 주어진 시퀀스에서 skipgrams를 생성하는 함수
# 텍스트 데이터의 순서 정보를 통해 단어 쌍을 만들어냄
skip_grams = [skipgrams(sample, vocabulary_size=vocab_size, window_size=10) for sample in encoded[:5]]
print(f'전체 샘플 수: {len(skip_grams)}')
>>> 전체 샘플 수: 5
# skip_grams[0]에 skipgrams로 형성된 데이터셋 3개만 확인
pairs, labels = skip_grams[0][0], skip_grams[0][1]
print(f'3 pairs: {pairs[:3]}')
print(f'3 lables: {labels[:3]}')
>>>
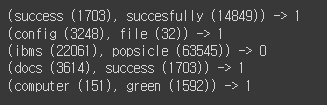
3 pairs: [[1703, 14849], [3248, 32], [22061, 63545]]
3 lables: [1, 1, 0]
# 첫번째 뉴스그룹 샘플에 대해 생긴 pairs와 labels의 개수
# pairs는 skip-grams에 대한 단어 쌍을 포함하는 리스트이고
# labels는 해당 단어 쌍이 양성(positive)인지 음성(negative)인지를 나타내는 레이블(label) 값들을 포함하는 리스트
print(len(pairs))
print(len(labels))
>>>
2100
2100
for i in range(5):
print('({:s} ({:d}), {:s} ({:d})) -> {:d}'.format(
idx2word[pairs[i][0]], pairs[i][0],
idx2word[pairs[i][1]], pairs[i][1],
labels[i]
))
training_dataset = [skipgrams(sample, vocabulary_size=vocab_size, window_size=10) for sample in encoded[:5000]]]
len(training_dataset)
>>> 5000
3. 워드 임베딩 구축
# 워드 임베딩 구축
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Embedding, Reshape, Activation, Input, Dot
from tensorflow.keras.utils import plot_model
embedding_dim =100
# 중심 단어를 위한 임베딩 테이블
w_inputs = Input(shape=(1,), dtype='int32')
word_embedding = Embedding(vocab_size, embedding_dim)(w_inputs)
# 주변 단어를 위한 임베딩 테이블
c_inputs = Input(shape=(1,), dtype='int32')
context_embedding = Embedding(vocab_size, embedding_dim)(c_inputs)
dot_product = Dot(axes=2)([word_embedding, context_embedding])
dot_product = Reshape((1,), input_shape=(1,1))(dot_product)
output = Activation('sigmoid')(dot_product)
model = Model(inputs=[w_inputs, c_inputs], outputs=output)
model.summary() # 모델 정보 요약해서 보기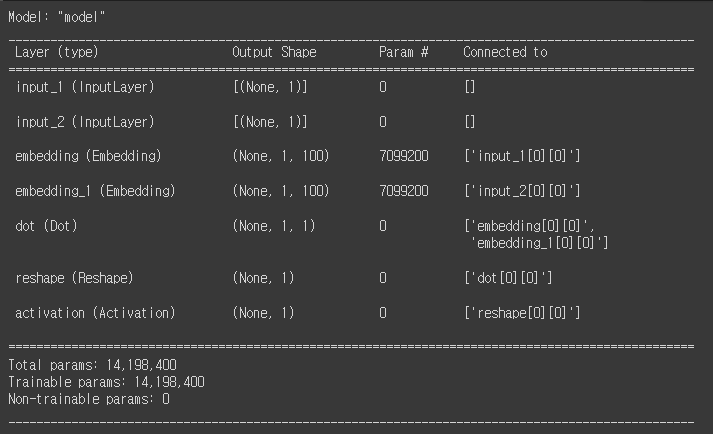
# 이중분류이기 때문에 (0,1) 손실함수는 binary_crossentropy를 사용
model.compile(loss='binary_crossentropy', optimizer='adam')
# 모델 정보에 대한 시각화
plot_model(model, to_file='model.png', show_shapes=True, show_layer_names=True)
4. 모델 학습
# 학습
for epoch in range(10):
loss = 0
for _, elem in enumerate(training_dataset):
first_elem = np.array(list(zip(*elem[0]))[0], dtype='int32')
second_elem = np.array(list(zip(*elem[0]))[1], dtype='int32')
labels = np.array(elem[1], dtype='int32')
X = [first_elem, second_elem]
Y = labels
loss += model.train_on_batch(X, Y)
print('Epoch: ', epoch+1, 'Loss: ', loss)
import gensim
f = open('vectors.txt','w')
f.write('{} {}\n'.format(vocab_size-1, embedding_dim))
vectors = model.get_weights()[0] # 첫번째 가중치를 저장
# print(vectors)
for word, i in tokenizer.word_index.items():
f.write('{} {}\n'.format(word, ' '.join(map(str, list(vectors[i, :])))))
f.close()
w2v = gensim.models.KeyedVectors.load_word2vec_format('./vectors.txt', binary=False)
w2v.most_similar(positive=['cat']) # 연관이 있다고 판단한 단어들과 유사도

728x90
반응형
LIST
'Python > NLP' 카테고리의 다른 글
| [파이썬, Python] 워드 임베딩(Word Embedding) - Word2Vec(C-BOW, Skipgram), FastText, GloVe (0) | 2023.07.23 |
|---|---|
| [파이썬, Python] 자연어처리 - 유사도 측정 실습 (0) | 2023.07.07 |
| [파이썬, Python] 임베딩(Embedding) - 임베딩 이론 (0) | 2023.07.07 |
| [파이썬, Python] 자연어처리 - 데이터 전처리 실습하기! (0) | 2023.07.06 |
| [파이썬, Python] 자연어처리 - 자연어 데이터 전처리 이론 (0) | 2023.07.05 |



