1. 워드 임베딩(Word Embedding)
- 단어를 컴퓨터가 이해하고, 효율적으로 처리할 수 있도록 단어를 벡터화 하는 기술
- 단어를 밀집 벡터(실수 값으로 이루어진 벡터)의 형태로 표현하는 방법
- 워드 임베딩 과정을 통해 나온 결과를 임베딩 벡터라고 함
- 워드 임베딩을 거쳐 잘 표현된 단어 벡터들은 계산이 가능하며, 모델에 입력으로 사용할 수 있음
1-1. 인코딩(Encoding)
- 기계는 자연어를 이해할 수 없기 때문에 데이터를 기계가 이해할 수 있도록 숫자 등으로 변환해주는 작업
- 자연어처리에서는 자연어를 수치화된 벡터로 변환하는 작업
1-2. 희소 표현(Sparse Representation)
- 원-핫 인코딩을 통해서 나온 원-핫 벡터들은 표현하고자 하는 단어의 인덱스의 값만 1이고, 나머지 인덱스에는 전부 0으로 표현되는 벡터 표현 방법
- 벡터 또는 행렬의 값이 대부분이 0으로 표현되는 방법을 희소 표현이라고 함
- 원-핫 인코딩에 의해 만들어지는 벡터를 희소 벡터라고 함
1-3. 희소 벡터의 문제점
- 희소 벡터의 특징은 단어의 개수가 늘어나면 벡터의 차원이 한없이 커진다는 것
- 원-핫 벡터는 벡터 표현 방식이 매우 단순하여, 단순히 단어의 출현 여부만을 벡터에 표시할 수 있음
- 희소 벡터를 이용하여 문장 혹은 텍스트간 유사도를 계산해보면 원하는 유사도를 얻기 힘듦
1-4. 밀집 표현(Dense Representation)
- 벡터의 차원이 조밀해졌다는 의미
- 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞추는 표현 방식
- 고차원의 정보를 저차원의 공간에 압축하여 표현
- 자연어를 밀집 표현으로 변환하는 인코딩 과정에서 0과 1의 binary 값이 아니라 연속적인 실수 값을 가질 수 있음
1-5. 밀집 표현의 장점
- 적은 차원으로 대상을 표현할 수 있음
- 더 큰 일반화 능력을 가지고 있음

1-6. 차원 축소(Dimensionality Reduction)
- 희소 벡터를 밀집 벡터의 형태로 변환하는 방법
- 머신러닝에서 많은 피처들로 구성된 고차원의 데이터에서 중요한 피처들만 뽑아 저차원의 데이터(행렬)로 변환하기 위해 사용
- PCA(Pricipal Component Analysis)
- 잠재 의미 분석(Latent Semantic Analysis, LSA)
- 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)
- SVD(Singular Value Decomposition, SVD)
2. Word2Vec
2-1. 분산 표현(Distributed Representation)
- 분포 가설이라는 가정 하에 만들어진 표현 방법
- 분포 가설: "비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다" 라는 가설
- 분포 가설의 목표는 단어 주변의 단어들, window(텍스트 데이터를 처리할 때 고려할 주변 단어의 개수) 크기에 따라 정의되는 문맥의 의미를 이용해 단어를 벡터로 표현(분산 표현) 하는 것
- 분산 표현으로 표현된 벡터들은 원-핫 벡터처럼 차원이 단어 집합(vocab)의 크기일 필요가 없으므로, 벡터의 차원이 상대적으로 저차원으로 줄어듦
- 밀집 표현을 분산 표현이라 부르기도 함
- 희소 표현에서는 각각의 차원이 각각의 독립적인 정보를 갖고 있지만, 밀집에서는 하나의 차원이 여러 속성들이 버무려진 정보를 갖고 있음
- 밀집 표현을 이용한 대표적인 학습 방법이 Word2Vec 임
2-2. Word2Vec 이란?
- 분포 가설 하에 표현한 분산 표현을 따라는 워드 임베딩 모델
- Google이 2013년도 처음 공개
- 중심 단어와 주변의 단어들을 사용하여 단어를 예측하는 방식으로 임베딩을 만듦
- Word2Vec의 학습 방식에는 두가지 방식
- CBOW(Continuous Bag of Words)
- Skip-Gram
2-3. CBOW(Continuous Bag of Words)
[위키독스]Word2Vec
09-02 워드투벡터(Word2Vec)
앞서 원-핫 벡터는 단어 벡터 간 유의미한 유사도를 계산할 수 없다는 단점이 있음을 언급한 적이 있습니다. 그래서 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를…
wikidocs.net
- 주변에 있는 단어들을 보고 중간에 있는 단어(타켓 단어)를 예측하는 방법
- 주변 단어(context)는 타겟 단어(target word)의 직전 n개 단어와 직후 n개 단어를 의미하며, 이 범위를 윈도우(window)라고 부르고, n을 윈도우 사이즈라고 함
- 문장 하나에 대해 한 번만 학습을 진행하는 것은 아깝기 때문에 sliding window 방식을 사용하여 하나의 문장을 가지고 여러 개의 학습 데이터 셋을 만듦
- Word2Vec은 최초로 입력으로 one-hot-vector를 받는데, 1*V크기의 one-hot-vector의 각 요소와 hidden layer N개의 각 노드는 1대 1 대응이 이뤄져야 하므로 가중치 행렬 W의 크기는 V x N이 됨
- 학습 코퍼스의 단어가 10,000개, hidden layer의 노드를 300개로 지정하였을 때, 가중치 행렬(W)은 10,000 * 300
각각의 가중치 행렬은 랜덤한 값으로 초기화되어 있고, 학습 시 target word를 맞추는 과정에서 W가 계속해서 조정됨 - 예를들어 4개의 단어들이 target word 예측에 사용될 때 각각의 단어들에 해당하는 W의 임베딩 벡터들 4개의 평균을 사용함
- 평균 벡터는 두 번째 가중치 행렬 W'과 곱해지며 곱해진 결과로는 target word의 원-핫 벡터와 크기가 동일한 벡터를 얻을 수 있음
- 최종 출력 값 벡터는 다중 클래스 분류 문제를 위한 일종의 스코어 벡터이며 0과 1사이의 값을 가지는데 이는 중심 단어일 확률을 나타냄
- 스코어 벡터 값은 정답 레이블에 해당하는 target word의 원-핫 벡터 내의 1의 값에 가까워져야 함
- 스코어 벡터와 원-핫 벡터의 오차를 줄이기 위해 손실함수(Cross-Entropy) 함수를 사용


2-4. Skip-gram
- 중심 단어에서 주변 단어를 예측
- 중심 단어를 sliding window 하면서 학습 데이터를 증강
- 중심 단어를 가지고 주변 단어를 예측하는 방법이기 때문에 projection layer 에서 벡터들 간의 평균을 구하는 과정이 없으며 대신 output layer을 통해 벡터가 2n개 만큼 나옴
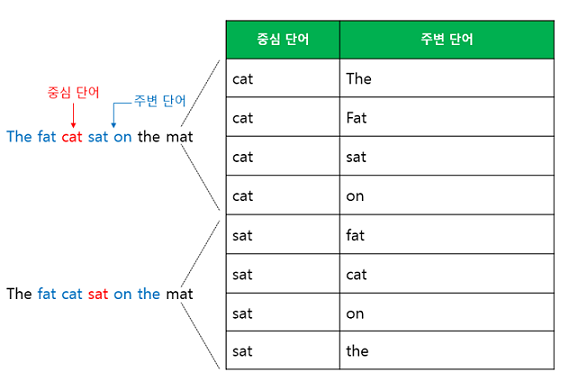
2-5. CBOW vs Skip-gram
- Skip-gram이 CBOW에 비해 여러 문맥을 고려하기 때문에 Skip-gram의 성능이 일반적으로 더 좋음
- Skip-gram이 단어당 학습 횟수가 더 많고, 임베딩 조정 기회가 많으므로 더 정교한 임베딩의 조정 기회가 많으므로 더 정교한 임베딩 학습이 가능
" 작고 귀여운 강아지 문 앞에 앉아 있다 "
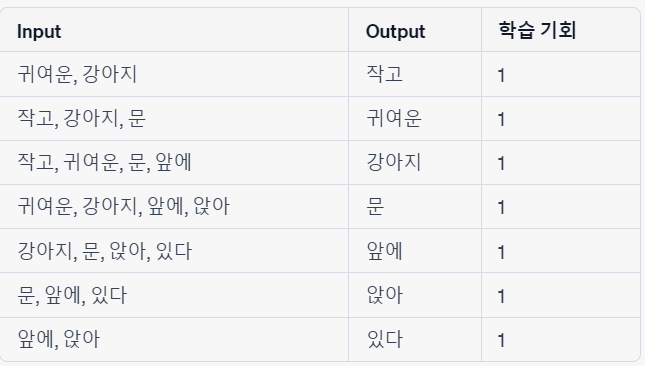
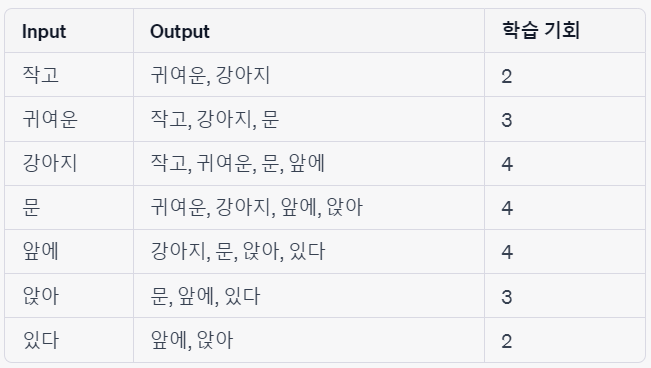
2-6. Word2Vec의 한계점
- 단어의 형태학적 특성을 반영하지 못함
- 예) teach, teacher, teachers와 같이 세 단어는 의미적으로 유사한 단어지만 각 단어를 개별단어로 처리하여 세 단어 모두 벡터 값이 다르게 구성됨
- 단어 빈도 수의 영향을 많이 받아 희소 단어를 임베딩하기 어려움
- OOV(Out Of Vocabulary)의 처리가 어려움 -> 학습이 되지 않았기 때문
- 새로운 단어가 등장하면 데이터 전체를 다시 학습 시켜야 함
- 단어 사전의 크기가 클수록 학습하는데 오래걸림
- 단어 사전의 크기가 수 만개 이상인 경우, Word2Vec은 학습하기에 무거운 모델이 됨
2-7. Word2Vec의 학습 트릭
1️⃣ Subsampling Frequent Words
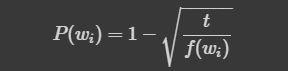
- 자연어 코퍼스에서 자주 등장하는 단어의 학습량을 확률적인 방법으로 줄이는 것(the, is, and ...)
- 등장 빈도가 높을수록 단어가 업데이트 될 기회가 많기 때문
- f(Wi)는 해당 단어가 말뭉치에 등장할 비율(해당 단어 빈도/전체 단어수)
- t는 사용자가 지정해주는 값으로, 연구팀에서는 0.00001을 권장
- 예) 만약 f(Wi)가 0.01로 나타나는 빈도 높은 단어는 위 식으로 계산은 P(Wi)가 0.9684이므로, 100번의 학습 기회 가운데 96번 정도는 학습에서 제외하게 됨
- 등장 비율이 적어 P(Wi)가 0에 가깝다면 해당 단어가 등장할 때마다 빼놓지 않고 학습
- 학습량을 효과적으로 줄여 계산량을 감소시키는 전략
2️⃣ Negative Sampling
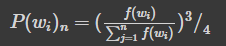
- 학습하는 중심 단어와 주변 단어들 외에, 이 단어들과 별 연관이 없는 수많은 단어의 임베딩까지 업데이트하는 것은 비효율적임
- 무작위로 네거티브 샘플들을 선택하여 하나의 중심 단어에 대해 [주변단어 + 네커티브샘플들]로만 구성된 작은 단어 집합을 만들어서 학습하면 훨씬 효율적으로 학습할 수 있을 것
- positive sample은 1로, negative sample은 0으로 간주하는 binary classification 형식의 학습 방법을 사용
- 모델을 학습할 때 기존의 Skip-gram과 다르게, target words에 대해서 단어 사전의 subset에 대해서만 학습을 진행할 수 있으므로 효율적으로 학습
- 예) "작고 귀여운 고양이 문 앞에 앉아 있다."라는 문장에서, "고양이"라는 단어를 학습할 때, window size = 2라고 가정할 경우, 주변 단어(Positive sampling)은 '작고', '귀여운', '문', '앞에'
- Negative sample은 '앉아', '있다'와 같은 이웃되지 않은 단어를 학습에 포함
[위키독스] Negative Sampling
09-04 네거티브 샘플링을 이용한 Word2Vec 구현(Skip-Gram with Negative Sampling, SGNS)
네거티브 샘플링(Negative Sampling)을 사용하는 Word2Vec을 직접 케라스(Keras)를 통해 구현해봅시다. ## 1. 네거티브 샘플링(Negative Samp…
wikidocs.net
3. FastText
- 분포 가설하에 표현한 분산 표현을 따르는 또 다른 임베딩 모델
- 2017년 페이스북에서 공개한 워드 임베딩 기법
[위키독스] FastText
09-06 패스트텍스트(FastText)
단어를 벡터로 만드는 또 다른 방법으로는 페이스북에서 개발한 FastText가 있습니다. Word2Vec 이후에 나온 것이기 때문에, 메커니즘 자체는 Word2Vec의 확장이라고…
wikidocs.net
3-1. FastText 동작 원리
- <, >는 단어의 경계를 나타내기 위한 특수 기호
- 단어를 <, >로 감싼 후, 설정한 n-gram의 값에 따라 앞에서부터 단어를 쪼갬
- 마지막에 본 단어를 설명하기 위해 <, >으로 감싸진 전체 단어를 하나 추가함
- n-gram 설정은 최소값과 최대값을 설정할 수 있음
- 예) apple을 n-gram = 3
- <ap, app, ppl, ple, le> + < apple > 6개 임베딩
- n-gram의 최소값 3, 최대값 4로 설정
- <ap, app, appl, ppl, pple, ple, le> + < apple >
3-2. FastText의 장점
- 오타나 모르는 단어에 대한 대응이 가능
- 단어 집합 내 빈도 수가 적었던 단어에 대한 대응
- 자연어 코퍼스 내 노이즈에 대응
4. GloVe
- GloVe(Global Vectors for Word Representation)
- 2014년에 미국 스탠포드대학에서 개발
- 카운트 기반과 예측 기반을 모두 사용하는 방법론
- Word2Vec과 같은 예측기반 방법론은 임베딩 벡터가 윈도우 크기 내에서만 주변 단어를 고려하기 때문에 코퍼스의 전체적인 통계 정보를 반영하지 못함
- LSA의 메커니즘이었던 카운트 기반의 방법과 Word2Vec의 메커니즘이었던 예측 기반의 방법론 두 가지를 모두 사용
[위키독스]GloVe
09-05) 글로브(GloVe)
글로브(Global Vectors for Word Representation, GloVe)는 카운트 기반과 예측 기반을 모두 사용하는 방법론으로 2014년에 미국 스탠포드대학에서…
wikidocs.net

'Python > NLP' 카테고리의 다른 글
| [파이썬, Python] 워드 임베딩 구축하기! (0) | 2023.07.23 |
|---|---|
| [파이썬, Python] 자연어처리 - 유사도 측정 실습 (0) | 2023.07.07 |
| [파이썬, Python] 임베딩(Embedding) - 임베딩 이론 (0) | 2023.07.07 |
| [파이썬, Python] 자연어처리 - 데이터 전처리 실습하기! (0) | 2023.07.06 |
| [파이썬, Python] 자연어처리 - 자연어 데이터 전처리 이론 (0) | 2023.07.05 |



