📄사용할 예제 - sklearn의 손글시 데이터셋
[데이터셋 정보] https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html
sklearn.datasets.load_digits
Examples using sklearn.datasets.load_digits: Recognizing hand-written digits Recognizing hand-written digits A demo of K-Means clustering on the handwritten digits data A demo of K-Means clustering...
scikit-learn.org
1. 손글씨 데이터셋 살펴보기
from sklearn.datasets import load_digits
# 데이터셋 객체 생성
digits = load_digits()
digits

✅ 데이터셋에서 어떤 항목들이 있는지 알아보기
digits.keys()
>>> dict_keys(['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR'])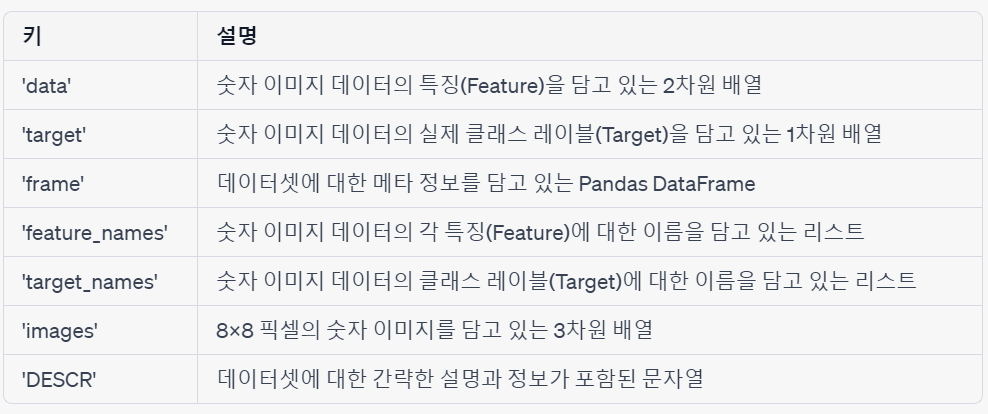
✅ 숫자 이미지 데이터 알아보기
data = digits['data']
data.shape
>>> (1797, 64) # 1791개의 데이터와 64개의 필드(컬럼)
data
✅ 첫번째 데이터 알아보기
data[0]
✅ 데이터들을 시각화하여 알아보기
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 5, figsize=(14, 8))
print(fig) # fig 객체
print(axes) # subplot을 그리는 객체

fig, axes = plt.subplots(2, 5, figsize=(14, 8))
for i, ax in enumerate(axes.flatten()): # 2차원의 axes 객체를 1차원으로 평탄화(flatten(): 다차원 배열을 평탄화)하여 반복
ax.imshow(data[i].reshape((8,8)), cmap='gray') # data들을 8x8로 재구성하여 이미지를 그레이스케일로 나타냄
ax.set_title(target[i]) # 정답 데이터를 제목으로 설정
2. 정규화(Min-Max Scaling)
- 데이터의 범위를 조정하여 일정한 차원로 맞추는 작업
- 데이터의 값을 특정 범위로 조정하는 방법으로, 주로 0과 1 사이의 범위로 조정
- 데이터의 분포가 정규 분포를 따르지 않을 때 사용될 수 있
data[0]
✅ MinMaxScaler로 이미지 데이터 정규화하기
from sklearn.preprocessing import MinMaxScaler
# scaler 객체 생성
scaler = MinMaxScaler()
# fit_transform(): 정규화
scaled = scaler.fit_transform(data)
scaled[0]
✅ 학습데이터와 검증데이터 분리하기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(scaled, target, test_size=0.2, random_state=10)
X_train.shape, X_test.shape
>>>((1437, 64), (360, 64))
y_train.shape, y_test.shape
>>> ((1437,), (360,))3. SVM(Support Vector Machine)
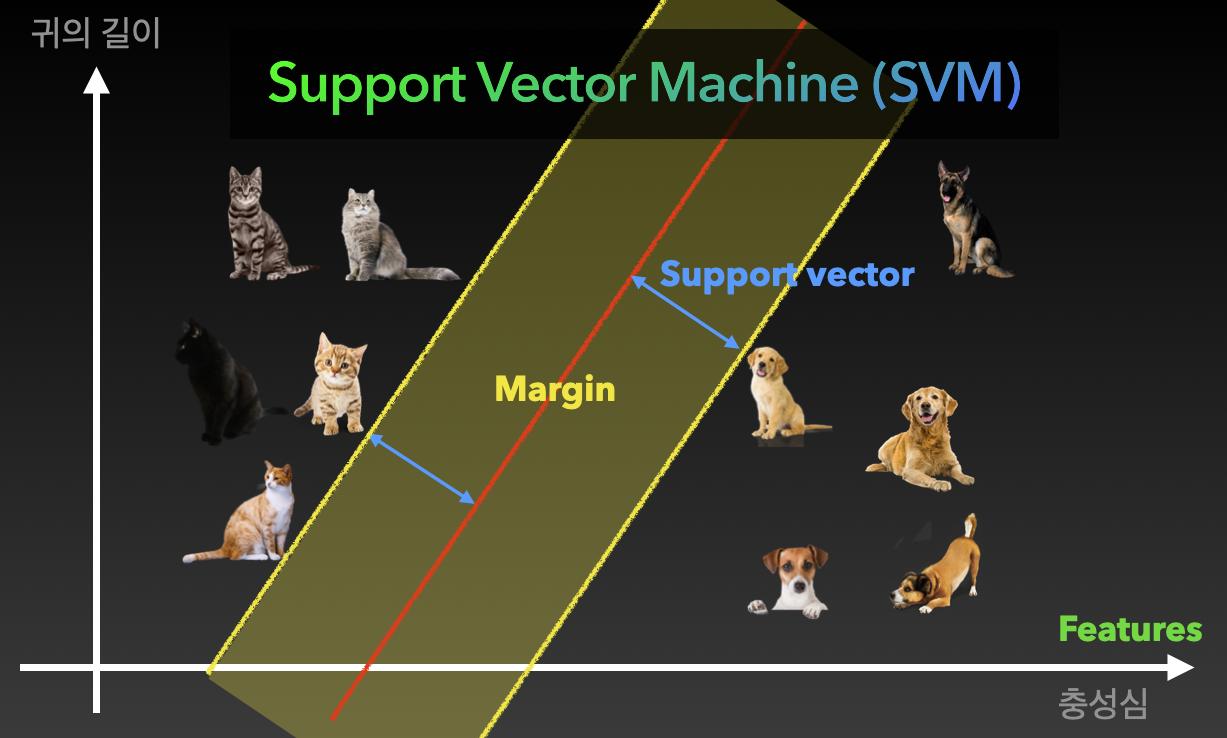
- 지도 학습(Supervised Learning) 알고리즘 중 하나로, 주로 분류(Classification)와 회귀(Regression) 문제에 사용
- 두 클래스로부터 최대한 멀리 떨어져 있는 결정 경계를 찾는 분류기(이진분류, binary classifier)로 특정 조건을 만족하는 동시에 클래스를 분류하는 것을 목표로 함
✅ SVC 모델로 데이터 학습 및 예측하기
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 모델 객체 생성
model =SVC()
# 학습
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 정확도
accuracy_score(y_test, y_pred)
>>> 0.9861111111111112
✅ 첫번째 검증데이터와 예측데이터를 시각화 하여 보기
print(y_test[0], y_pred[0])
plt.imshow(X_test[0].reshape(8,8))
plt.show()
✅ subplot을 이용하여 검증 데이터와 예측된 데이터를 시각화하여 보기
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 5, figsize=(14,8))
for i, ax in enumerate(axes.flatten()):
ax.imshow(X_test[i].reshape(8,8), cmap='gray')
ax.set_title(f'Label: {y_test[i]}, Pred: {y_pred[i]}')

'Python > ML&DL' 카테고리의 다른 글
| [파이썬, Python] 머신러닝 - 6️⃣ LightGBM (0) | 2023.06.18 |
|---|---|
| [파이썬, Python] 머신러닝 - 5️⃣ 랜덤 포레스트(Random Forest) (0) | 2023.06.18 |
| [파이썬, Python] 머신러닝 - 3️⃣ 로지스틱 회귀(Logistic Regression) (0) | 2023.06.15 |
| [파이썬, Python] 머신러닝 - 2️⃣ 의사결정나무(Decision Tree) (2) | 2023.06.14 |
| [파이썬, Python] 머신러닝 - 1️⃣ 선형 회귀(Linear Regression) (0) | 2023.06.14 |



