728x90
반응형
SMALL
1. 타이타닉 데이터셋 살펴보기
📄 타이타닉 데이터셋(csv)
import numpy as np
import pandas as pd
df = pd.read_csv('https://bit.ly/fc-ml-titanic')
df.head()
✅ 각 피쳐들의 뜻 알아보기

✅ 데이터셋 정보 한눈에 보기
df.info()
2. 데이터 전처리
- 넓은 범위의 데이터 정제 작업을 뜻함
- 필요 없는 데이터를 삭제하고, 필요한 데이터만 취하는 것, null 값이 있는 행을 삭제하는 것, 정규화, 표준화 등의 많은 작업들을 포함하고 있음
- 머신러닝, 딥러닝 실무에서도 전처리가 50% 이상의 중요도를 차지함
2-1. 독립변수와 종속변수 나누기
# 독립변수: 성별, 가격, 나이, 좌석등급
# 종속변수: Survived(생존여부)
feature = ['Sex', 'Fare', 'Age', 'Pclass']
label = ['Survived']
df[feature].head()
df[label].head()
# 종속변수의 종류와 개수 알아보기
df[label].value_counts() # 0: 사망, 1: 생존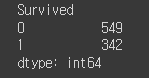
2-2. 결측치 처리
df.info()
# null값의 합계
df.isnull().sum()
# 나이 결측치를 평균으로 처리
df['Age'] = df['Age'].fillna(df['Age'].mean())
df['Age']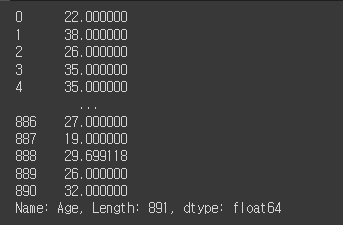
2-3. 라벨 인코딩(Label Encoding)
- 문자(Categorical)를 수치(Numerical)로 변환
df['Sex'].value_counts()
# 성별을 남자면 1, 여자면 0을 반환하는 함수 만들기
def convert_sex(data):
if data == 'male':
return 1
elif data == 'female':
return 0
# apply 를 통해 해당 열에 함수 적용
df['Sex'] = df['Sex'].apply(convert_sex)
df.head()
✅ LabelEncoder로 라벨 인코딩 하기
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder() # 객체 생성
# 라벨 인코딩 할 피쳐의 종류와 개수 알아보기
df['Embarked'].value_counts()
le.fit_transform(df['Embarked']) # 항구에 해당하는 데이터를 숫자로 바꿔줌
# 라벨인코딩의 정보를 보고싶을때
le.classes_ # 0: 'C', 1: 'Q', 2: 'S', 3: NaN
>>> array(['C', 'Q', 'S', nan], dtype=object)2-4. 원 핫 인코딩(One Hot Encoding)
- 독립적인 데이터는 별도의 컬럼으로 분리하고 각각 컬럼에 해당 값에만 1, 나머지는 0 값을 갖게 하는 방법
- 예) 머신러닝 알고리즘은 'C:0, Q:1, S:2, Nan:3' 데이터의 관계성을 찾아 'Q + Q = S'라고 학습을 할 수 있음 -> 관계성을 끊어주기 위해 원 핫 인코딩을 사용
- pd.get_dummies()
# df['Embarked']를 수치로 바꾸어 새로운 파생변수로 저장
df['Embarked_num'] = le.fit_transform(df['Embarked'])
df.head()
✅ 원 핫 인코딩 하기
pd.get_dummies(df['Embarked_num'])
✅ 학습데이터와 검증데이터를 분할
# 학습데이터(80%), 검증데이터(20%)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df[feature], df[label], test_size = 0.2, random_state=10)
X_train.shape, X_test.shape
>>> ((712, 4), (179, 4))
y_train.shape, y_test.shape
>>> ((712, 1), (179, 1))📍 머신러닝에 있어서 데이터셋 전처리가 중요한 이유!
1️⃣ 불완전한 데이터 처리
- 실제 데이터는 불완전하고 누락된 값, 이상치, 잡음 등이 포함될 수 있음
- 전처리를 통해 이러한 불완전한 데이터를 처리하고, 누락된 값에 대한 적절한 대체나 제거를 수행함으로써 모델의 성능을 향상시킬 수 있음
2️⃣ 데이터 변환 및 정규화
- 머신 러닝 모델은 일반적으로 수치형 데이터를 다루기 때문에, 범주형 데이터나 텍스트 데이터를 수치형으로 변환해야 할 때가 있습음
- 변수들의 범위가 서로 다른 경우에는 정규화나 표준화를 통해 변수들을 동일한 범위로 조정하는 작업이 필요
- 데이터 변환 및 정규화를 통해 모델의 수렴 속도를 개선하고, 모델의 성능을 일관되게 유지
3️⃣ 차원 축소
- 고차원 데이터셋에서는 변수의 수가 많아서 모델의 학습이 어려울 수 있음
- 차원 축소 기법을 사용하여 데이터의 차원을 줄여주는 전처리 작업이 필요
- 차원 축소를 통해 모델의 복잡도를 감소시키고, 학습과 예측 효율성 증대
4️⃣ 데이터의 일반화
- 전처리는 모델이 훈련 데이터에서 학습한 특정 패턴에 지나치게 의존하지 않고, 새로운 데이터에도 일반화할 수 있도록 도와줌
- 데이터셋 전처리를 통해 모델의 일반화 성능을 향상시킬 수 있으며, 과적합을 방지할 수 있음

728x90
반응형
LIST
'Python > ML&DL' 카테고리의 다른 글
| [파이썬, Python] 머신러닝 - 4️⃣ 서포트 벡터 머신(Support Vector Machine) (0) | 2023.06.18 |
|---|---|
| [파이썬, Python] 머신러닝 - 3️⃣ 로지스틱 회귀(Logistic Regression) (0) | 2023.06.15 |
| [파이썬, Python] 머신러닝 - 2️⃣ 의사결정나무(Decision Tree) (2) | 2023.06.14 |
| [파이썬, Python] 머신러닝 - 1️⃣ 선형 회귀(Linear Regression) (0) | 2023.06.14 |
| [파이썬, Python] 머신러닝(Machine Learning)과 사이킷런(Scikit-learn) 모듈 (0) | 2023.06.14 |



