728x90
반응형
SMALL
이전 글에서 사용하던 csv 파일 예제로 데이터프레임을 다뤄보자.
1. isin()
- 정의한 list에 있는 데이터를 색인하려는 경우 사용하는 함수
- 주어진 시리즈(Series)나 데이터프레임(DataFrame) 객체에서 각 요소가 주어진 값들 중 하나와 일치하는지 여부를 확인하는 데 사용
company =['플레디스', 'SM']
df[df['company'].isin(company)] # df에서 company열에 ['플레디스','SM']이 있는 데이터들을 뽑아옴
df['company'].isin(company)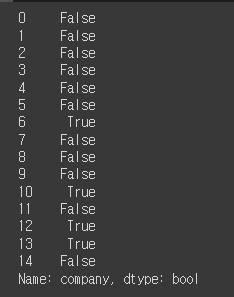
df.loc[df['company'].isin(company)]
2. 결측값(Null, NaN)
- Null은 비어있는 값, 결측값이라고 부름(데이터가 들어가있지 않음)
2-1. 결측값 확인하기
df.info()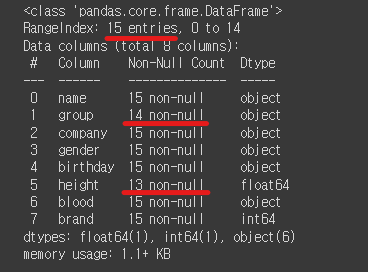
df.isna() # 결과가 True, False로 나옴
df.isnull()
df[df['group'].isna()]['name'] # group이 NaN인 사람의 데이터
# 결측값이 아닌지에 대한 여부 (데이터가 있는)
df.notnull()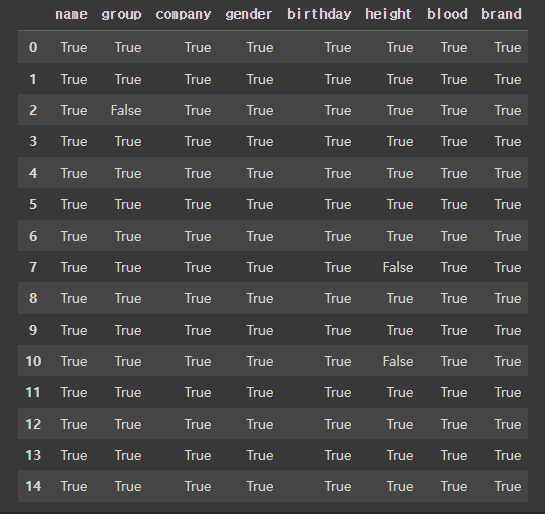
df[df['group'].notnull()]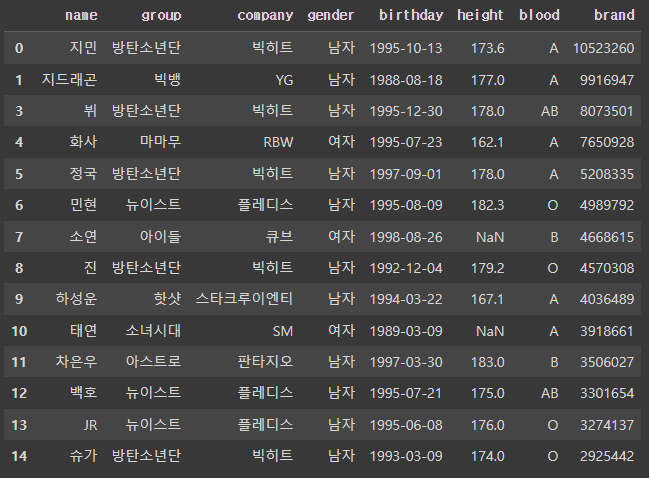
# 그룹이 있는 연예인의 이름, 키, 혈액형을 loc를 사용하여 출력['name', 'height', 'blood']
df.loc[df['group'].notnull()][['name', 'height', 'blood']]
df['height']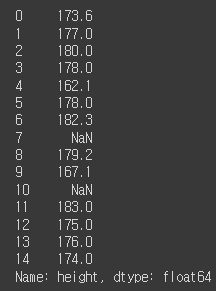
# fillna(): 결측값을 채워주는 함수
df['height'].fillna(0) # NaN인 값을 0으로 채움
df['height'].fillna(0, inplace=True) # 자동저장 옵션, height가 NaN인 값을 0으로 채워서 저장함
df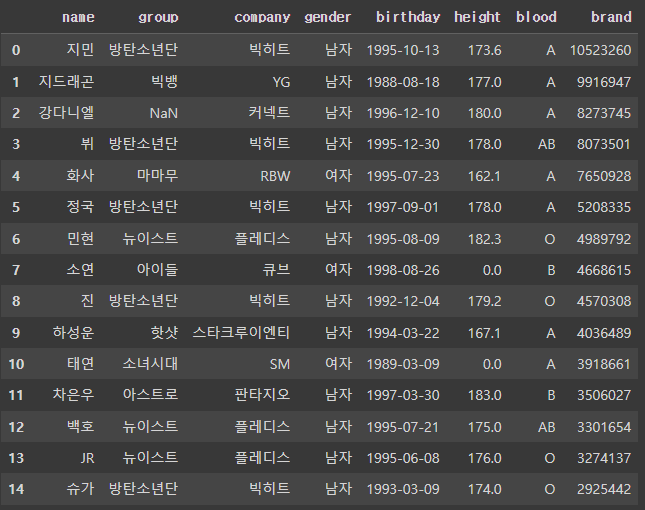
# 망가진 데이터를 다시 재저장함
df
df2 = df.copy()
df2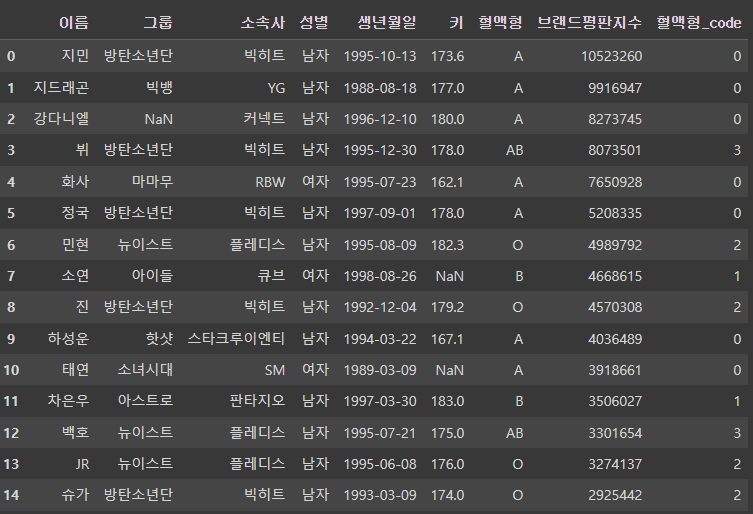
# 키 컬럼의 평균값으로 NaN채우기
height = df2['키'].mean()
df2['키'] = df['키'].fillna(height)
df2['키']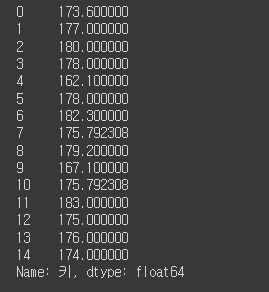
# 키 컬럼의 중앙값(50%에 해당하는 존재하는 값)으로 NaN채우기
height = df2['키'].median()
df2['키'] = df['키'].fillna(height)
df2['키']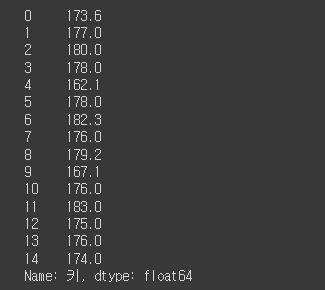
# 결측값이 있는 행을 제거
# 결측값 한개라도 있는 경우 행을 제거
df.dropna()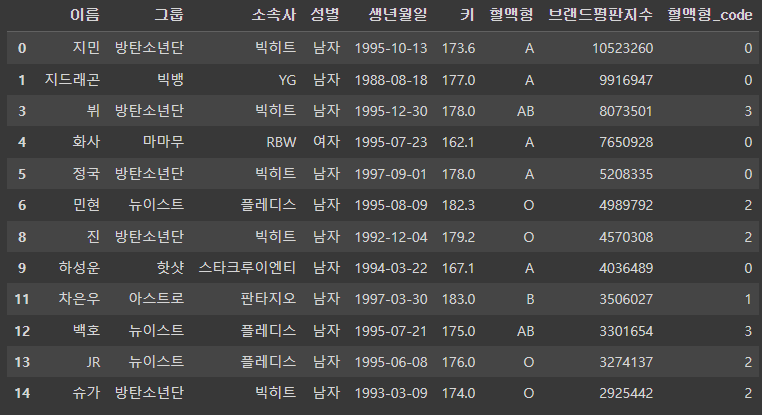
df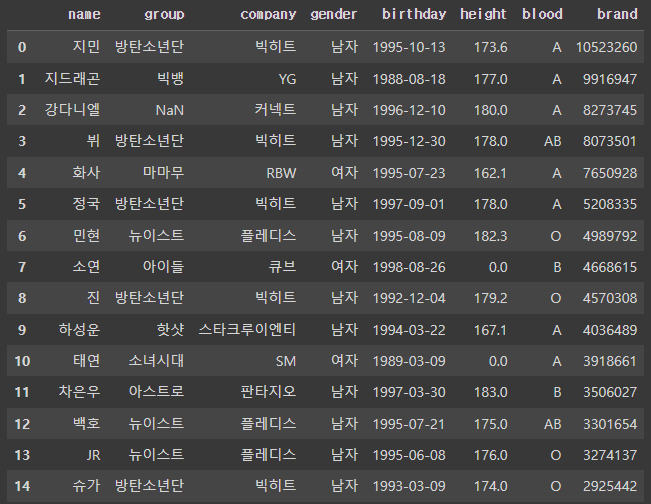
# 결측값이 있는 열을 제거(거의 하지 않음!!)
df.dropna(axis=1)

728x90
반응형
LIST



