728x90
반응형
SMALL
1. 판다스(Pandas)
- '웨스 맥키니'가 개발한 라이브러리
- 데이터 작업을 쉽고 직관적으로 설계된 빠르고 유연한 자료구조(데이터프레임)를 제공하는 모듈
1-1. 판다스 라이브러리 설치하기
!pip install pandas # 설치
import pandas as pd # 임포트1-2. Series와 DataFrame
- 2차원 표 데이터를 데이터프레임이라고 한다면, 1차원 표 데이터는 시리즈임
- 표의 데이터 부분을 values라고 부름
- 표의 행 이름을 index라고 부름
- 표의 열 이름을 columns라고 부름
- 시리즈는 values와 index로 이루어져 있고, 데이터프레임은 values, index, columns로 이루어져 있음
- 데이터프레임과 시리즈의 values는 넘파이의 ndarray 기반


✅ DataFrame
data1 = [[67, 93, 91],
[75, 54, 95],
[75, 91, 61],
[99, 94, 65],
[40, 65, 22]]
index1 = ['김사과','바나나','오렌지','이메론','포오도']
col1 = ['국어','영어','수학']
# DataFrame(데이터, 인덱스, 컬럼)
pd.DataFrame(data1)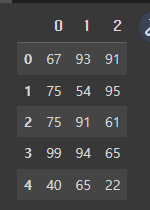
pd.DataFrame(data1, index1)
pd.DataFrame(data1, index1, col1)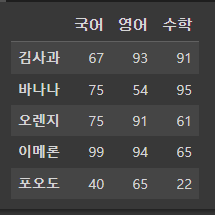
# index값을 지정하지 않고(숫자로자동으로 입력되게하고) 컬럼명은 입력하고 싶을 때
pd.DataFrame(data1, columns=col1)
df1 = pd.DataFrame(data1, index1, col1) # 변수에 저장
df1
df1.values
>>> array([[67, 93, 91],
[75, 54, 95],
[75, 91, 61],
[99, 94, 65],
[40, 65, 22]])
# Index지만 ndarray랑 똑같음(처리방법이 같음) , dtype='object': 데이터프레임의 요소가 stiring일 경우 object로 저장됨
df1.index
>>> Index(['김사과', '바나나', '오렌지', '이메론', '포오도'], dtype='object')
df1.columns
>>> Index(['국어', '영어', '수학'], dtype='object')
✅ 딕셔너리를 통해 데이터프레임 생성하기
# 딕셔너리를 사용하여 데이터프레임을 생성
dic1 = {
'국어': [67, 75, 75, 62, 98],
'영어': [93, 69, 81, 70, 45],
'수학': [91, 96, 82, 75, 87]
}
df2 = pd.DataFrame(data=dic1, index=index1)
df2
>>>✅ Series
# Series(데이터, 인덱스)
pd.Series(data2)
>>>
0 67
1 75
2 75
3 62
4 98
dtype: int64
pd.Series(data2, index1)
>>>
김사과 67
바나나 75
오렌지 75
이메론 62
포오도 98
dtype: int64
se1 =pd.Series(data2, index1) # 변수에 저장
se1.values
>>> array([67, 75, 75, 62, 98])
se1.index
>>> Index(['김사과', '바나나', '오렌지', '이메론', '포오도'], dtype='object')
2. CSV 파일 다루기
- CSV(Comma Separated Value)의 약자로 데이터를 쉼표로 구분한 파일
- 엑셀로 로딩할 수 있지만 쉼표로 구분된 csv가 더 가볍기 때문에 데이터로 많이 사용
[공공데이터] https://www.data.go.kr/
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
📄 예제로 사용할 cvs 파일
2-1. 구글 코랩에서 파일을 업로드하여 불러오기
- 런타임 재실행 되면 파일이 사라지기 때문에 매번 업로드 해야하는 단점

# pd.read_csv(CSV파일 경로, 인코딩 방법)
pd.read_csv('/content/korean-idol.csv')2-2. 구글 드라이브에 파일을 저장하여 불러오기
# 구글드라이브에 파일을 저장하고 마운트하여 데이터프레임 만들기
pd.read_csv('/content/drive/MyDrive/KDT/Python/2. 데이터분석/korean-idol.csv')2-3. 다운로드 주소를 이용하여 불러오기
# 인터넷 주소(들어가면 csv파일이 다운받아지는)로 데이터프레임 만들기
pd.read_csv('http://bit.ly/ds-korean-idol')

3. 엑셀 파일 읽어오기
📄 예제로 사용할 엑셀 파일
pd.read_excel('/content/drive/MyDrive/KDT/Python/2. 데이터분석/korean-idol.xlsx')

728x90
반응형
LIST
'Python > Data Analysis' 카테고리의 다른 글
| [파이썬, Python] Pandas 모듈 - 4️⃣ 데이터프레임 복사하기, 행/열 추가 및 삭제하기 (0) | 2023.06.12 |
|---|---|
| [파이썬, Python] Pandas 모듈 - 3️⃣ 데이터 찾기 isin(), 결측값 알아보기 isna(), 결측값 제거하기 dropna() (0) | 2023.06.09 |
| [파이썬, Python] Pandas 모듈 - 2️⃣ 데이터프레임(DataFrame) 정보와 데이터프레임 다루기 (0) | 2023.06.08 |
| [파이썬, Python] Numpy 모듈 - 2️⃣ 행렬 연산자, arange, sort, 숫자 단일 연산 (0) | 2023.06.08 |
| [파이썬, Python] Numpy 모듈 - 1️⃣ 넘파이 모듈, ndarray 다루기(인덱싱, 슬라이싱) (0) | 2023.05.18 |



