1. 자연어(Natural Language)
- 프로그래밍 언어와 같이 인공적으로 만든 기계 언어와 대비되는 단어로, 우리가 일상에서 주로 사용하는 언어
1-1. 자연어처리(Natural Language Processing, NLP)
- 컴퓨터가 한국어나 영어와 같은 인간의 자연어를 읽고 이해할 수 있도록 돕는 인공지능의 한 분야
- 자연어에서 의미 있는 정보를 추출하여 활용
- 기계가 자연어의 의미를 이해하게 함
- 기계가 사람의 언어로 소통할 수 있게함
1-2. 자연어처리의 활용
- 문서 분류, 스팸 처리와 같은 분류 문제부터 검색어 추천과 같은 추천 기능, 음성 인식, 질의 응답, 번역 등의 다양한 분야에서 사용되고 있음
- 반복 업무 자동화
- 검색 효율 향상 및 검색 엔진 최적화
- 대규모 문서 분석 및 정리
- 소셜 미디어 분석
1-3. 용어 정리
1️⃣ 자연어이해(Natural Language Understanding, NLU)
- 자연어처리의 하위 집합
- 자연어이해 기술의 목적은 일반적으로 기계가 자연어의 실제 의미, 의도나 감정, 질문 등을 사람처럼 이해하도록 돕는 것
- 기계가 다양한 텍스트의 숨겨진 의미를 해석하려면 사전 처리 작업들과 추가 학습이 필요
- 텍스트에 명시적으로 나타나는 표지적인 정보 이외에 숨겨진 뜻을 파악
- 비 언어적인 신호(표정, 손짓, 몸짓)도 힌트로 사용될 수 있음
- 텍스트에서 의미있는 정보를 추출하는 기술과 상황을 통계적으로 학습시킬 수 있는 다량의 데이터가 필요함
2️⃣ 자연어생성(Natural Language Generation, NLG)
- 자연어처리의 하위 집합
- 기계가 정형화되지 않은 데이터나 정보를 이해하고 해석하여 자연어 형태로 표현하는 과정
- 기계가 사람의 언어를 직접 생성하도록 돕는 기술
- NLG는 기계가 일련의 계산 결과를 사람의 언어로 표현하도록 도와줌
2. 자연어처리에 대한 다양한 Task

2-1. Text Classification
- 텍스트(문서) 분류
- 단어, 문장, 문서 단위의 텍스트에 사전 정의된 카테고리 또는 클래스로 할당, 분류하는 작업
- 지도 학습(Supervised Learning) 방식을 기반
- 학습된 모델은 새로운 입력 텍스트를 받아들여 해당 텍스트의 카테고리를 예측
- Sentiment Analysis: 주어진 문장의 감정을 분류
- Abusing Detection: 주어진 문장의 어뷰징(핵, 치트 등) 여부를 판별
2-2. Information Retrieval and Document Ranking
- 정보검색과 문서 순위화
- 두 문서나 문장간 유사도를 결정하는 작업
- 사용자의 정보 요구를 이해하고, 그에 맞는 문서나 정보를 찾아 제공
- Text Similarity Task 는 document DB가 있을 때 query text에 대해서 가장 유사한 문서를 반환하는 것을 목표로 하는 retrieval 혹은 ranking 작업으로 확장될 수 있음
2-3. Text to Text Generation
- 텍스트를 입력으로 받아 목표를 달성하는 텍스트를 생성하는 작업
- 소스 언어의 텍스트를 의미를 유지한 채 타겟 언어의 텍스트로 번역하는 작업
- 여러 문서들의 의미를 유지한 채 더 짧은 버전의 텍스트로 요약하는 작업
- 포괄적인 관점에서 사람이 작성한 것 같은 텍스트를 생성하는 작업
2-4. Knowlegde bases, Entities and Relations
- 지식 기반, 의미론적인 엔티티나 관계를 파악하는 자연어처리 분야
예) Open AI는 2023년 5월 ChatGPT4 인공지능 봇을 공개하였다.객체로 뽑을 수 있는 것들
Open AI (조직, 기업)
2023년 5월 (날짜)
ChatGPT4 (product)
인공지능 (product)
2-5. Topics and Keywords
- 문서 혹은 문장 내의 주제나 키워드를 파악하는 자연어처리 분야
2-6. Chatbots
- 음성이나 문자를 통한 인간과의 대화를 통해서 특정한 작업을 수행하도록 제작된 컴퓨터 프로그램
- 정해진 규칙에 맞춰서 메시지를 입력하면 발화(그에 맞춘 답변)를 출력하는 규칙 기반 챗봇부터 문맥을 입력으로 받아 적절한 답변을 생성/검색하는 인공지능 기반 챗봇 등이 있음
2-7. Text Reasoning
- 주어진 지식이나 상식을 활용하여 일련의 추론 작업을 수행하는 작업
- 간단한 수학 문제들을 푼다고 생각해보면 일련의 계산 과정에 의해 답을 도출하게 되는데 그러한 일련의 계산 과정을 추론 과정이라고 함
2-8. Fake News and Fake Speech Detection
- 허위 혹은 오해의 소지가 있는 정보가 포함된 텍스트를 감지하고 필터링하는 작업
- 소셜 미디어 혹은 배포 중인 제품에서 발생하는 여뷰징 콘텐츠들을 필터링하기 위해 사용
2-9. Text to Data and vice-versa
- 자연어처리 작업 단일 모달인 텍스트 작업 뿐만 아니라, 입출력의 모달을 다양하게 활요할 수 있음
- 음성을 텍스트(STT)로 혹은 텍스트를 음성(TTS)으로 변환하는 작업이나, 텍스트를 이미지(Text to Image)로 변환하는 작업 등이 실무 또는 학회에서 많이 논의됨
3. 자연어처리 진행 순서
3-1. 문제 정의
- 문제에 대한 솔루션이 있어야 하고 명확하고 구체적일수록 알맞는 자연어처리 기술을 찾을 수 있음
3-2. 데이터 수집 및 분석
- https://paperswithcode.com/datasets?mod=texts&task=question-answering
- 다양한 학습데이터를 수집하기 위해 공개된 데이터셋, 유로 데이터셋 또는 웹 크롤링을 사용하여 수집
- 웹크롤링을 통해 데이터를 수집했다면 EDA(탐색적 데이터 분석) 및 분석 작업을 통해 데이터를 철저하게 검증해야 함
- 정답 레이블이 필요하다면 수집한 데이터에 레이블을 붙여야 함
- 레이블을 자동으로 붙일 수 있는 툴: M-Turk, SELECTSTART
Papers with Code - Machine Learning Datasets
269 datasets • 100103 papers with code.
paperswithcode.com
3-3. 데이터 전처리
- 학습에 용이하게 데이터를 수정/보완하는 작업
- 자연어처리 진행 과정에서 데이터가 차지하는 비중이 매우 높기 때문에 데이터를 수집하고 전처리하는 과정이 매우 중요함
- 토큰화(Tokenization): 주어진 데이터셋에서 문장이나 토큰이라 불리는 단위로 나누는 작업
- 정제(Cleaning): 갖고 있는 데이터셋으로부터 노이즈 데이터(이상치, 편향 등)를 제거하는 작업
- 정규화(Normalization): 표현 방법이 다른 데이터들을 통합시켜서 같은 항목으로 합치는 작업
3-4. 모델링
- 자연어처리 작업은 대부분 단어 토큰들을 결과로 표현
- 언어 모델을 사용하며 문장 혹은 단어에 확률을 할당하여 컴퓨터가 처리할 수 있도록 함
- 자연어처리 분야에는 많은 언어 모델들이 있음
- 어떤 언어 모델이 내가 풀고자 하는 문제에 가장 적합한지 확인
- 자연어 작업 처리에 특화된 세부적인 테크닉들이 다 다르므로 SOTA (최근 트렌드 모델들을 통칭)모델들을 확인해야 함
- [SOTA모델확인] https://paperswithcode.com/area/natural-language-processing
Papers with Code - Natural Language Processing
Browse 607 tasks • 1818 datasets • 2100
paperswithcode.com
📍 기차를 타기 위해 기차역을 가능 중에 차가 막혀서 결국 기차를 ???
➡️ ??? 에 들어갈 단어나 글자가 무엇인지 확률로 나타냄
내렸다 0.1
놓쳤다 0.7
멈췄다 0.1
달려갔다 0.1
3-5. 모델 학습 및 평가
- 데이터가 준비되어 있고 모델 구조와 학습 방법을 결정해다면 언어 모델을 학습
- GPU 환경에서 진행
- 가용할 수 있는 인프라에 맞춰 학습 파라미터를 설정하고 학습을 시작
- 학습 도중, 학습 종료 후 평가
- 정량 평가, 정성 평가
3-6. 실무에서의 평가 진행 과정
- 준비된 데이터셋을 Train/Valid/Test 데이터셋으로 분할
- Train 데이터셋으로 모델을 학습하고, 중간 중간 Valid 데이터셋으로 학습 진행 상황 체크
- 문제 없이 학습이 종료되었다면 Test 데이터셋과 추가 정량 평가 데이터셋들로 최종 모델에 대한 정량 성능 지표를 측정(MSE, Precision, f1 score 등)
- 정셩 평가를 수행하기 위해 정성 평가 데이터셋을 만들고 평가자를 모집하여 블라인드 테스트를 진행
- 정량 평가 및 정성 평가 결과에 따라 모델 사용 여부를 결정
4. Huggingface
- 기계 학습을 사용하여 애플리케이션을 구축하기 위한 도구를 개발하는 회사
- 자연어 처리 애플리케이션으로 구축된 Transformers 라이브러리와 사용자가 기계 학습 모델 및 데이터셋을 공유할 수 있는 플랫폼으로 유명
- Huggingface에 업로드된 모델들은 기본적으로 PretrainedModel 클래스를 상속받고 있음
- [페이지] https://huggingface.co/
Hugging Face – The AI community building the future.
The AI community building the future. Build, train and deploy state of the art models powered by the reference open source in machine learning.
huggingface.co
# transformers 라이브러리 다운로드
!pip install transformers
# huggingface_hub 다운로드
!pip install huggingface_hub
✅ huggingface 모델 허브 API 접근하여 Pretrained 된 BERT모델 가져오기
from huggingface_hub import HfApi
AutoModel: 모델에 관한 정보를 처음부터 명시하지 않아도 설정해줌
# 예) BERT모델을 사용하는 경우 모델의 상세정보를 확인할 필요 없이 Model ID만으로 손쉽게 모델 구성이 가능
from transformers import AutoModel, AutoTokenizer, BertTokenizer
# Model ID
BERT_MODEL_NAME = 'bert-base-cased'
token = '허깅페이스 계정 토큰'
# pretrained된 모델을 가져옴
bert_model = AutoModel.from_pretrained(BERT_MODEL_NAME, use_auth_token=token)
✅ 단어를 분절하여 토큰화할 객체 생성
bert_tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
print(bert_tokenizer.vocab_size) # 토큰화된 단어사전의 크기
>>> 28996
✅ 단어사전에서 10개의 토큰만 출력하기
for i, key in enumerate(bert_tokenizer.get_vocab()):
print(key)
if i > 10:
break
>>>
Russian
##nar
websites
##virus
trousers
##dit
auto
Prefecture
Hillary
ally
attacking
Den
✅ 아래 예시를 bert 사용하여 토큰화하기
sample_1 = 'welcome to the natural language class'
sample_2 = 'welcometothenaturallanguageclass' # 띄어쓰기없음
# return_tensors: 토큰을 어떤 type으로 반환할지 설정(tf, pt, np)
tokenized_input_text = bert_tokenizer(sample_1, return_tensors='pt') # 파이토치형 텐서로 반환
for key, value in tokenized_input_text.items():
print('{}:\n\t{}'.format(key, value))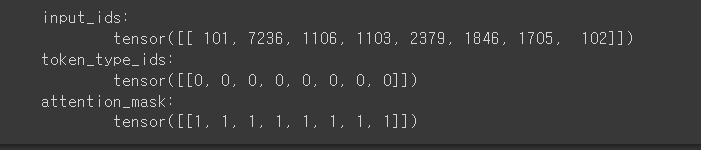
- input_ids: 토큰의 인덱스를 나타냄
- token_type_ids: 문장의 세그먼트 정보를 나타냄(각 토큰이 첫 번째 문장인지(0), 두 번째 문장인지(1)를 구분하는 역할)
- attention_mask: 실제 단어 토큰은 1로 표시되고, 패딩 토큰은 0으로 표시
tokenized_input_text = bert_tokenizer(sample_2, return_tensors='pt') # 파이토치형 텐서
for key, value in tokenized_input_text.items():
print('{}:\n\t{}'.format(key, value))
- ids가 24226, 12602 처럼 10000이 넘어가는 큰 인덱스값이라면 나중에 추가되었을 수 있음
- 띄어쓰기가 없을 때 토큰화가 다르게 됨
✅ 토큰화 결과 출력하기
print(tokenized_input_text['input_ids'])
print(tokenized_input_text.input_ids) # 위와 동일
print(tokenized_input_text['token_type_ids'])
print(tokenized_input_text.token_type_ids)
print(tokenized_input_text['attention_mask'])
print(tokenized_input_text.attention_mask)
>>> tensor([[ 101, 7236, 2430, 10681, 24226, 12602, 19514, 6718, 2176, 1665,
17223, 102]])
tensor([[ 101, 7236, 2430, 10681, 24226, 12602, 19514, 6718, 2176, 1665,
17223, 102]])
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
✅ tokenize(): 어떻게 토큰화 되었는지 정보를 반환하는 메서드
# 어떻게 토큰화 되었는지 알고 싶을 때
tokenized_text = bert_tokenizer.tokenize(sample_1)
print(tokenized_text)
>>> ['welcome', 'to', 'the', 'natural', 'language', 'class']
✅ encode(): 문장의 토큰을 인코딩
input_ids = bert_tokenizer.encode(sample_1)
print(input_ids)
>>> [101, 7236, 1106, 1103, 2379, 1846, 1705, 102] # 토큰은 6개, 인덱스값은 8개
✅ decode(): 인코딩된 토큰을 복호화(토큰 정보)
decoded_ids = bert_tokenizer.decode(input_ids)
print(decoded_ids)
>>> [CLS] welcome to the natural language class [SEP]📍 처음 101과 끝 102는 시작과 끝을 알리는 스페셜 토큰 - [CLS] ,[SEP]
✅ sample_2 토큰화
tokenized_text = bert_tokenizer.tokenize(sample_2)
print(tokenized_text)
>>> ['welcome', '##to', '##the', '##nat', '##ural', '##lang', '##ua', '##ge', '##c', '##lass']
✅ 토큰 인코딩
input_ids = bert_tokenizer.encode(sample_2)
print(input_ids)
>>> [101, 7236, 2430, 10681, 24226, 12602, 19514, 6718, 2176, 1665, 17223, 102]
✅ 인코딩된 토큰 복호화(토큰)
decoded_ids = bert_tokenizer.decode(input_ids)
print(decoded_ids)
>>> [CLS] welcometothenaturallanguageclass [SEP]
✅ [CLS] ,[SEP]와 같은 스페셜 토큰을 보고싶지 않을 경우 add_special_tokens 옵션 설정
tokenized_text = bert_tokenizer.tokenize(sample_1, add_special_tokens=False)
print(tokenized_text)
>>> ['welcome', 'to', 'the', 'natural', 'language', 'class']
input_ids = bert_tokenizer.encode(sample_1, add_special_tokens=False)
print(input_ids)
>>> [7236, 1106, 1103, 2379, 1846, 1705]
decoded_ids = bert_tokenizer.decode(input_ids)
print(decoded_ids)
>>> welcome to the natural language class
✅ 토큰화할 때 원하는 길이를 지정하여 토큰화할 경우 max_length 옵션 설정
# max_length 가 실제 데이터보다 값이 작을 때
tokenized_text = bert_tokenizer.tokenize(
sample_1,
add_special_tokens=False,
max_length=5,
truncation=True
)
print(tokenized_text)
>>> ['welcome', 'to', 'the', 'natural', 'language']
# 토큰 인코딩
input_ids = bert_tokenizer.encode(
sample_1,
add_special_tokens=False,
max_length=5,
truncation=True
)
print(input_ids)
>>> [7236, 1106, 1103, 2379, 1846]
# 인코딩된 토큰 복호화
decoded_ids = bert_tokenizer.decode(input_ids)
print(decoded_ids)
>>> welcome to the natural language
# max_length 가 실제 데이터보다 값이 클 때
tokenized_text = bert_tokenizer.tokenize(
sample_1,
add_special_tokens=False,
max_length=20,
padding='max_length', # max_length의 나머지 부분을 padding으로 채움
truncation=True
)
print(tokenized_text)
>>> ['welcome', 'to', 'the', 'natural', 'language', 'class', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']
✅ 실제 데이터값보다 max_length 값이 더 클 때 padding 옵션 설정
tokenized_text = bert_tokenizer.tokenize(
sample_1,
add_special_tokens=False,
max_length=20,
padding='max_length' # 나머지 부분을 [PAD]라는 토큰으로 채움.
)
print(tokenized_text)
>>> ['welcome', 'to', 'the', 'natural', 'language', 'class', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']
input_ids = bert_tokenizer.encode(
sample_1,
add_special_tokens=False,
max_length=20,
padding='max_length' # 인덱스 값은 0으로 채워짐
)
print(input_ids)
>>> [7236, 1106, 1103, 2379, 1846, 1705, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
decode_ids = bert_tokenizer.decode(input_ids)
print(decode_ids)
>>> welcome to the natural language class [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
✅ padding의 토큰과 토큰 인덱스값 알아보기
print(bert_tokenizer.pad_token) # padding의 토큰
>>> [PAD]
print(bert_tokenizer.pad_token_id) # padding 토큰의 인덱스값
>>> 0✅ 한글 문장 토큰화
kor_text = '아직도 목요일이네'
# [UNK], [UNK]: 두 개의 토큰으로 보고 등록되지 않은 단어임
tokenized_text = bert_tokenizer.tokenize(
kor_text,
add_special_tokens=False,
max_length=10,
padding='max_length' # 나머지 부분을 [PAD]라는 토큰으로 채움
)
print(tokenized_text)
>>> ['[UNK]', '[UNK]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']📍 한글의 경우 토큰화 불가, 띄어쓰기를 기준으로 토큰화 후 정의되지 않은 토큰으로 분류
✅ 토큰화 정보
tokenized_input_text = bert_tokenizer(kor_text, return_tensors='pt') # 파이토치형 텐서
for key, value in tokenized_input_text.items():
print('{}:\n\t{}'.format(key, value)) # [UNK]의 인덱스값이 100
tokenized_text = bert_tokenizer.tokenize(
kor_text,
max_length=20
)
print(tokenized_text)
>>> ['[UNK]', '[UNK]']
input_ids = bert_tokenizer.encode(
kor_text,
max_length=20
)
print(input_ids)
>>> [101, 100, 100, 102]
decode_ids = bert_tokenizer.decode(input_ids)
print(decode_ids)
>>>[CLS] [UNK] [UNK] [SEP]📍한국어의 토큰화는 한글로 학습되지 않은 모델로 토큰화를 할 수 없음!
✅ 한국어 텍스트 모델 불러오기
multi_bert_model = AutoModel.from_pretrained('bert-base-multilingual-cased')
multi_bert_tokenizer = AutoTokenizer.from_pretrained('bert-base-multilingual-cased')
print(multi_bert_tokenizer.vocab_size) # 한국어 단어사전의 개수가 119547개
>>> 119547
text = '한국인이 알아볼 수 있는 한국어를 사용합니다'
tokenized_text = multi_bert_tokenizer.tokenize(
text,
max_length=20
)
print(tokenized_text) # '##': 다른 단어들과 붙여쓸 수 있음
>>> ['한국', '##인이', '알', '##아', '##볼', '수', '있는', '한국', '##어를', '사', '##용', '##합', '##니다']
input_ids = multi_bert_tokenizer.encode(
text,
max_length=20
)
print(input_ids)
>>> [101, 48556, 56789, 9524, 16985, 101450, 9460, 13767, 48556, 80940, 9405, 24974, 33188, 48345, 102]
decode_ids = multi_bert_tokenizer.decode(input_ids)
print(decode_ids)
>>> [CLS] 한국인이 알아볼 수 있는 한국어를 사용합니다 [SEP]
✅ 정의되지 않은 텍스트 토큰화
unk_text = '한꾺인먄 얄야뽈 쓔 있뉸 한뀩어룰 샤용햡니땨'
tokenized_text = multi_bert_tokenizer.tokenize(
unk_text,
max_length=20
)
print(tokenized_text)
>>> ['[UNK]', '[UNK]', '[UNK]', '[UNK]', '[UNK]', '[UNK]']
input_ids = multi_bert_tokenizer.encode(
unk_text,
max_length=20
)
print(input_ids)
>>> [101, 100, 100, 100, 100, 100, 100, 102]
decode_ids = multi_bert_tokenizer.decode(input_ids)
print(decode_ids)
>>> [CLS] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [SEP]
# 등록되지 않은 한국어는 UNK
✅ 새로운 글자를 토큰으 추가하기
added_token_num = multi_bert_tokenizer.add_tokens(['한꾺인먄','얄야뽈','있뉸'])
print(added_token_num)
>>> 3
✅ 추가 후 토큰화
tokenized_text = multi_bert_tokenizer.tokenize(unk_text, add_special_tokens=False)
print(tokenized_text)
>>> ['한꾺인먄', '얄야뽈', '[UNK]', '있뉸', '[UNK]', '[UNK]']
input_ids = multi_bert_tokenizer.encode(unk_text, add_special_tokens=False)
print(input_ids)
>>> [119547, 119548, 100, 119549, 100, 100]
decoded_ids = multi_bert_tokenizer.decode(input_ids)
print(decoded_ids)
>>> 한꾺인먄 얄야뽈 [UNK] 있뉸 [UNK] [UNK]
✅ special token 추가하기
special_token_text = '[DAD]아빠[/DAD]가 방에 들어가신다' # special token 을 추가
tokenized_text = multi_bert_tokenizer.tokenize(special_token_text, add_special_tokens=False)
print(tokenized_text) # special token 을 인식하지 못함!
>>> ['[', 'DA', '##D', ']', '아', '##빠', '[', '/', 'DA', '##D', ']', '가', '방', '##에', '들어', '##가', '##신', '##다']
input_ids = multi_bert_tokenizer.encode(special_token_text, add_special_tokens=False)
print(input_ids) # 대괄호나 영어에 대한 인덱스값으로 나옴
>>> [164, 47855, 11490, 166, 9519, 119008, 164, 120, 47855, 11490, 166, 8843, 9328, 10530, 71568, 11287, 25387, 11903]
decoded_ids = multi_bert_tokenizer.decode(input_ids)
print(decoded_ids)
>>> [ DAD ] 아빠 [ / DAD ] 가 방에 들어가신다
✅ additional_special_tokens() 사용
# special token 등록하기
special_token_text = '[DAD]아빠[/DAD]가 방에 들어가신다' # special token 을 추가
# add_special_tokens(): key(additional_special_tokens):value로 데이터를 넣음
added_token_num = multi_bert_tokenizer.add_special_tokens({'additional_special_tokens': ['[DAD]', '[/DAD]']})
✅ 토큰화 결과 확인
special_token_text = '[DAD]아빠[/DAD]가 방에 들어가신다' # special token 을 추가
# add_special_tokens=False 로 두었지만 내가 등록한 special token은 별도로 관리하기 때문에 꺼주려면 다른 옵션을 주어야 함
tokenized_text = multi_bert_tokenizer.tokenize(special_token_text, add_special_tokens=False)
print(tokenized_text)
>>> ['[DAD]', '아', '##빠', '[/DAD]', '가', '방', '##에', '들어', '##가', '##신', '##다']
input_ids = multi_bert_tokenizer.encode(special_token_text, add_special_tokens=False)
print(input_ids)
>>> [119550, 9519, 119008, 119551, 8843, 9328, 10530, 71568, 11287, 25387, 11903]
decoded_ids = multi_bert_tokenizer.decode(input_ids)
print(decoded_ids)
>>> [DAD] 아빠 [/DAD] 가 방에 들어가신다
✅내가 등록한 special tokens을 보고싶지 않을 때
decoded_ids = multi_bert_tokenizer.decode(input_ids, skip_special_tokens=True)
print(decoded_ids)
>>> 아빠 가 방에 들어가신다
✅ 아래 샘플들을 토큰화하고 결과 비교하기
# 입력을 문장의 리스트로 구성하여 tokenizer의 입력으로 사용하면 출력 결과도 배열로 저장됨
sample_list = ['아빠가 방에 들어가신다', '[DAD]아빠[/DAD]가방에들어가신다']
tokens = multi_bert_tokenizer(
sample_list, # 리스트로 넣음
padding=True # 길이를 지정해주지 않았기 때문에 둘 중 긴 길이만큼 찍히고 없으면 Padding
)
for i in range(len(sample_list)):
print('Tokens (int) : {}'.format(tokens['input_ids'][i]))
print('Tokens (str) : {}'.format([multi_bert_tokenizer.convert_ids_to_tokens(s) for s in tokens['input_ids'][i]])) # input_id를 str로 변환함
print('Tokens (attn_mask) : {}'.format(tokens['attention_mask'][i])) # 글자가 있는부분은 1, 없는부분은 0으로 찍히는 masks
print()
✅ [MASK] 토큰 예측하기
masked_text = '아빠가 [MASK] 들어가신다'
tokenized_text = multi_bert_tokenizer.tokenize(masked_text)
print(tokenized_text)
>>> ['아', '##빠', '##가', '[MASK]', '들어', '##가', '##신', '##다']
# 마스크 토큰을 채워주는 라이브러리
from transformers import pipeline
nlp_fill = pipeline('fill-mask', model='bert-base-multilingual-cased')
nlp_fill(masked_text)
📍마스크 토큰 부분에 들어갈 글자를 채워주는데 완벽한 문장을 구현할 수 없음 -> multi_bert모델은 한국어 전용이 아니기 때문!

'Python > NLP' 카테고리의 다른 글
| [파이썬, Python] 워드 임베딩(Word Embedding) - Word2Vec(C-BOW, Skipgram), FastText, GloVe (0) | 2023.07.23 |
|---|---|
| [파이썬, Python] 자연어처리 - 유사도 측정 실습 (0) | 2023.07.07 |
| [파이썬, Python] 임베딩(Embedding) - 임베딩 이론 (0) | 2023.07.07 |
| [파이썬, Python] 자연어처리 - 데이터 전처리 실습하기! (0) | 2023.07.06 |
| [파이썬, Python] 자연어처리 - 자연어 데이터 전처리 이론 (0) | 2023.07.05 |



