1. 클러스터(Clusters)
- 비슷한 특성을 가지고 있는 항목들을 함께 그룹화
- 클러스터링은 주어진 데이터를 특정 기준에 따라 여러 그룹으로 분류하는 작업
- 비슷한 특성을 가진 데이터끼리 클러스터를 형성하고, 서로 다른 클러스터들 간에는 구분되는 특성을 가짐
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs # 가상의 클러스터를 생성하여 분류나 군집 문제를 위한 가상 데이터셋을 생성
✅ 가상의 데이터셋을 생성하여 클러스터 예제를 실습하여보자.
# X: 독립변수
# y: 종속변수
# n_samples=100: 100개의 행(100개의 데이터)
# centers=3: y값의 결과를 0,1,2 3가지 분류로 만듦
# random_state=10: 랜덤값 고정
X, y = make_blobs(n_samples=100, centers=3, random_state=10)
X = pd.DataFrame(X) # 열 이름을 [0, 1]로 자동으로 생성
X
# 레이블값
y
# scatterplot으로 시각화
sns.scatterplot(x=X[0], y=X[1], hue=y)
✅ KMeans 모델로 확인
from sklearn.cluster import KMeans
# n_clusters=3: 비지도학습으로 k수를 미리 지정
km = KMeans(n_clusters=3)
# 학습
km.fit(X)
# 예측
pred = km.predict(X)
# 예측한 결과값을 hue 설정하여 확인
sns.scatterplot(x=X[0], y=X[1], hue=pred)
✅k값을 4로 설정할 때
# k=4로 설정
km = KMeans(n_clusters=4)
km.fit(X)
pred = km.predict(X)
sns.scatterplot(x=X[0], y=X[1], hue=pred)
✅ inertia_: 비지도 학습 평가값, 하나의 클러스터 안에 중심점으로부터 각각의 데이터 거리를 합한 값
km.inertia_
>>> 154.03820014871644
✅ 그럼 미리 지정해야하는 k값을 최적으로 군집화하려면 어떻게 설정하는게 좋을까?
inertia_list = []
for i in range(2, 11): # 최소 2개의 그룹으론 나눠지기 때문에 2부터 시작
km = KMeans(n_clusters=i)
km.fit(X)
inertia_list.append(km.inertia_)
inertia_list # k=2~10 일때 중심점으로부터의 거리 합
>>>
[976.8773336900748,
186.3658862010144,
154.5169216889871,
130.02425208172426,
112.82290280054046,
98.0312059792646,
85.25679840216795,
73.68616199317509,
65.95628288509153]
# 완만하게 줄어드는 구간 -> 군집 속에서 다시 쪼개짐
sns.lineplot(x=range(2, 11), y=inertia_list)
💡 k=3일 때 가장 최적으로 군집화
📄예제에 사용한 csv 파일
# 데이터 불러오기
mkt_df = pd.read_csv('/content/drive/MyDrive/KDT/Python/4.머신러닝 딥러닝/marketing.csv')
mkt_df
# 안보이는 컬럼까지 보기
pd.set_option('display.max_columns', 40)
✅mkt_df의 정보 보기
mkt_df.info()

✅ 모델 학습에 필요없는 컬럼 제거하기
mkt_df.drop('ID', axis=1, inplace=True)
✅ 수치형 데이터 확인하기
mkt_df.describe()
✅ 출생연도의 이상치 확인하기
mkt_df['Year_Birth'].sort_values()
✅ 1900년도 이상의 출생연도 데이터만 저장
mkt_df = mkt_df[mkt_df['Year_Birth'] > 1900]
✅ 수입 컬럼의 이상치 확인하기
mkt_df['Income'].sort_values(ascending=False)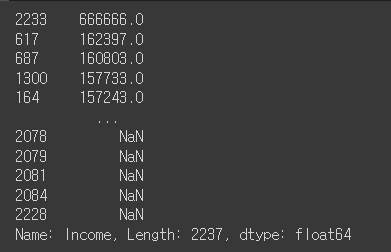
✅ 결측지 비율 알아보기
mkt_df.isna().mean()
# mkt_df = mkt_df[mkt_df['Income'] < 200000] # NaN이 저장되지 않음
mkt_df = mkt_df[mkt_df['Income'] != 666666] # NaN까지 같이 제거
# Income의 데이터 다시 확인
mkt_df['Income'].sort_values(ascending=False)
✅ 결측지 제거 후 재저장
mkt_df = mkt_df.dropna()
✅ 데이터들의 타입 알아보기
mkt_df.info()
✅ Dt_Customer 의 dtype을 datetime으로 변환하기
mkt_df['Dt_Customer'] = pd.to_datetime(mkt_df['Dt_Customer'])
✅ 마지막으로 가입된 사람을 기준으로 가입 날짜(달) 구하기
mkt_df['Dt_Customer'].sort_values(ascending=False)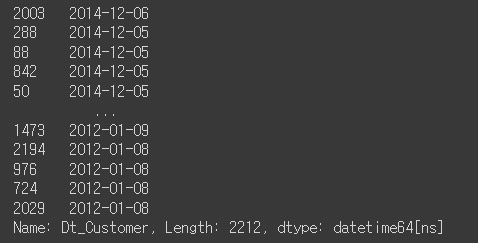
# 가장 마지막에 가입한 사람의 연도
mkt_df['Dt_Customer'].dt.year.max()
>>> 2014
mkt_df['Dt_Customer'].dt.year * 12 + mkt_df['Dt_Customer'].dt.month
# 새로운 파생변수로 만들기
mkt_df['pass_age'] = (mkt_df['Dt_Customer'].max().year * 12 + mkt_df['Dt_Customer'].max().month) - (mkt_df['Dt_Customer'].dt.year * 12 + mkt_df['Dt_Customer'].dt.month)
mkt_df['pass_age']
✅ Dt_Customer 컬럼 지우기
mkt_df.drop('Dt_Customer',axis=1, inplace=True)
✅ MntWines, MntFruits, MntMeatProducts, MntFishProducts, MntSweetProducts, MntGoldProds를 합친 새로운 파생변수를 만들기
mkt_df['Total_mnt'] = mkt_df[['MntWines', 'MntFruits', 'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts', 'MntGoldProds']].sum(axis=1)
✅ Kidhome, Teenhome을 합친 새로운 파생변수를 만들기
mkt_df['Children'] = mkt_df[['Kidhome','Teenhome']].sum(axis=1)
✅ Kidhome, Teenhome 컬럼 지우기
mkt_df.drop(['Kidhome', 'Teenhome'], axis=1, inplace=True)
✅ mkt_df 정보 재확인
mkt_df.info()
✅ Education 열의 데이터와 개수 알아보기
mkt_df['Education'].value_counts()
✅ Marital_Status열의 데이터와 개수 알아보기
mkt_df['Marital_Status'].value_counts()
✅ Marital_Status에서 파트너(Partner)와 싱글(Single)로 묶어줄 내용을 합치기
mkt_df['Marital_Status'] = mkt_df['Marital_Status'].replace({'Married':'Partner','Together':'Partner','Single':'Single','Divorced':'Single','Widow':'Single','Alone':'Single','Absurd':'Single','YOLO':'Single'})
mkt_df['Marital_Status'].unique()
>>> array(['Single', 'Partner'], dtype=object)
✅ 원 핫 인코딩 하기
mkt_df = pd.get_dummies(mkt_df, columns=['Education','Marital_Status'])3. 데이터 스케일링(Data Scailing)
- 데이터를 특정한 스케일로 통일하는 것
- 데이터를 모델링 하기 전에 거치는 것이 성능 향상에 좋음
- 다차원의 값들을 비교 분석하기 쉽게 만들어주며, 자료의 오버플로우나 언더플로우를 방지하여 최적화 과정에서의 안정성 및 수렴 속도를 향상
- 오버플로우: 숫자가 표현할 수 있는 범위를 벗어나서 최댓값보다 큰 값을 표현하려고 할 때 발생
- 예) 8비트로 표현 가능한 숫자의 범위가 0부터 255까지라고 가정하면, 256 이상의 값을 표현하려고 할 때 오버플로우가 발생
- 언더플로우(Underflow): 언더플로우는 숫자가 표현할 수 있는 범위를 벗어나서 최솟값보다 작은 값을 표현하려고 할 때 발생
- 예) 8비트로 표현 가능한 숫자의 범위가 0부터 255까지라고 가정하면, 음수 값이 아닌 0보다 작은 값을 표현하려고 할 때 언더플로우가 발생
3-1. 스케일링의 종류
- StandardScaler: 평균과 표준편차 사용, (X - 평균) / 표준편차
- MinMaxScaler: 최대/최소값이 각각 1과 0이 되도록 스케일링, (X - min) / (Max - Min)
- MaxAbsScaler: 최대절대값과 0이 각각 1, 0이 되도록 스케일링
- RobustScaler: 중앙값(Median)과 IQR(사분위수) 사용 -> outlier의 영향을 최소화 , (X - Q2) / (Q3 - Q1)
✅ 스케일링 예시
movie = {'naver':[2,4,6,8,10], 'netflix': [1,2,3,4,5]}
movie = pd.DataFrame(movie)
movie
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
# 객체 생성
min_max_scaler = MinMaxScaler()
# 학습시키고 scailing
# fit_transform(): 학습시키고 데이터를 scaler에 맞춰 변환시켜주는 메소드
min_max_movie= min_max_scaler.fit_transform(movie)
pd.DataFrame(min_max_movie, columns=['naver','netflix']) # 최소 최대값의 범위를 맞춰줌
3-2. mkt_df에 스케일링 적용하기
✅ StandardScaler 적용해보기
# StandardScaler: 평균과 표준편차 사용, (X - 평균) / 표준편차
ss = StandardScaler()
# 학습 및 스케일링
ss.fit_transform(mkt_df)
✅ 데이터프레임으로 보기
pd.DataFrame(ss.fit_transform(mkt_df))
✅ mkt_df 데이터에 스케일링 적용하기
ss_df = pd.DataFrame(ss.fit_transform(mkt_df),columns=mkt_df.columns)
✅ RobustScaler 적용해보기
# RobustScaler: 중앙값(Median)과 IQR(사분위수) 사용 -> outlier의 영향을 최소화 , (X - Q2) / (Q3 - Q1)
rs = RobustScaler()
# 학습 및 스케일링 적용 후 mkt_df의 컬럼과 맞춤
rs_df = pd.DataFrame(rs.fit_transform(mkt_df),columns=mkt_df.columns)
rs_df
✅ MinMaxScaler 적용해보기
# MinMaxScaler: 최대/최소값이 각각 1과 0이 되도록 스케일링, (X - min) / (Max - Min)
mm = MinMaxScaler()
mm_df = pd.DataFrame(mm.fit_transform(mkt_df),columns=mkt_df.columns)
mm_df
4. KMeans
- KMeans 클러스터링 알고리즘은 n개의 중심점을 찍은 후에, 이 중심점에서 각 점 간의 거리가 합이 가장 최소화가 되는 중심점 n의 위치를 찾고 이 중심점에서 가까운 점들을 중심점을 기준으로 묶는 알고리즘
- 중심점은 각 군집의 데이터의 평균값을 위치로 가지게 됨
- 클러스터의 수(k)를 정해줘야 함
- 중심점을 측정할 때 처음에 랜덤으로 중심점의 위치를 찾기 때문에 잘못되면 중심점의 점간의 거리가 Global Optimum인 최소값을 찾는게 아니라 중심점이 Local Optimum에 수렴하여 잘못된 분류를 할 수 있음.
✅ 최적의 k(클러스터 수)를 알아보기
inertia_list = []
for i in range(2, 11): # 최소 2개의 그룹으론 나눠지기 때문에 2부터 시작
km = KMeans(n_clusters=i, random_state=10)
km.fit(mm_df)
inertia_list.append(km.inertia_)
inertia_list
>>>
[2884.52947013434,
2405.195207071574,
2139.189131737316,
1877.7127959780694,
1728.5409997814195,
1554.9009258180042,
1414.241283074918,
1329.5629856639696,
1257.1281654839]
sns.lineplot(x=range(2, 11), y=inertia_list)
5. 실루엣 스코어
- 각 군집 간의 거리가 얼마나 효율적으로 분리 되어있는지를 나타냄
- 다른 군집과의 거리는 떨어져 있고 동일 군집끼리의 데이터는 서로 가깝게 잘 뭉쳐 있다는 의미
- 실루엣 분석은 실루엣 계수를 기반으로 하는데, 실루엣 계수는 개별 데이터가 가지는 군집화 지표
from sklearn.metrics import silhouette_scorescore = []
for i in range(2, 11): # 최소 2개의 그룹으론 나눠지기 때문에 2부터 시작
km = KMeans(n_clusters=i, random_state=10)
km.fit(mm_df)
pred = km.predict(mm_df)
score.append(silhouette_score(mm_df, pred)) # 실제 데이터프레임과 예측값을 넣어 실루엣 스코어를 얻은걸 리스트에 추가
score
>>>
[0.27069493833875846,
0.24864017540307504,
0.2720374467213452,
0.3169512485472221,
0.2687842581624041,
0.3023437795916352,
0.32784071353619376,
0.3103663650975524,
0.32666800120305484]
# 스코어 수가 가장 큰 x값이 cluster의 k값으로 설정하는 것이 가장 깔끔함
sns.lineplot(x=range(2, 11), y=score)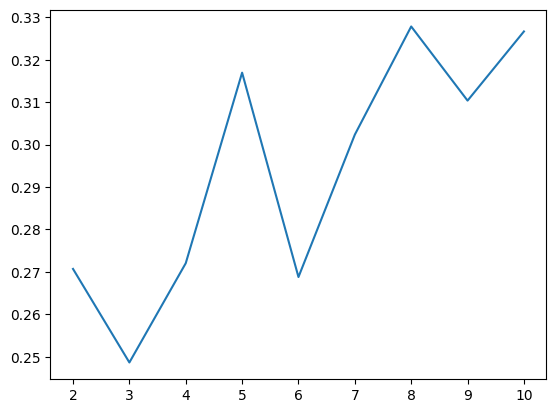
✅ k=8을 적용하여 다시 학습시키기
km = KMeans(n_clusters=8, random_state=10)
# 학습
km.fit(mm_df)
# 예측
pred = km.predict(mm_df)
pred
>>> array([2, 2, 7, ..., 2, 5, 3], dtype=int32)
✅해당 데이터에 파생변수로 군집 번호를 생성하기
mkt_df['label'] = pred
# 군집된 종류 개수 알아보기
mkt_df['label'].value_counts()

'Python > ML&DL' 카테고리의 다른 글
| [파이썬, Python] 파이토치(Pytorch)란❓ & 파이토치의 특징 알아보기!🧐 (0) | 2023.06.23 |
|---|---|
| [파이썬, Python] 평가지표 - MSE, MAE, RMSE (0) | 2023.06.23 |
| [파이썬, Python] 머신러닝 - 6️⃣ LightGBM (0) | 2023.06.18 |
| [파이썬, Python] 머신러닝 - 5️⃣ 랜덤 포레스트(Random Forest) (0) | 2023.06.18 |
| [파이썬, Python] 머신러닝 - 4️⃣ 서포트 벡터 머신(Support Vector Machine) (0) | 2023.06.18 |



